[Research Highlights] [Recent Projects] [Selected Publications]
國立政治大學
大仁樓307
National Chengchi University,
Dept. of Computer Science,
Da-Ren Building 3F, Taipei,
TAIWAN
02-2939-3091#62028
|
|
主持人: 廖文宏
Wen-Hung Liao 電子郵件(E-mail) : whliao at nccu.edu.tw |
學歷:
Education
|
|
| 研究領域: 電腦視覺、圖型識別、深度學習、人機互動 Research Interests: Computer Vision, Pattern Recognition, Deep Learning, Human-Computer Interaction Common Threads:
|
|
|
(Dec. 2023)
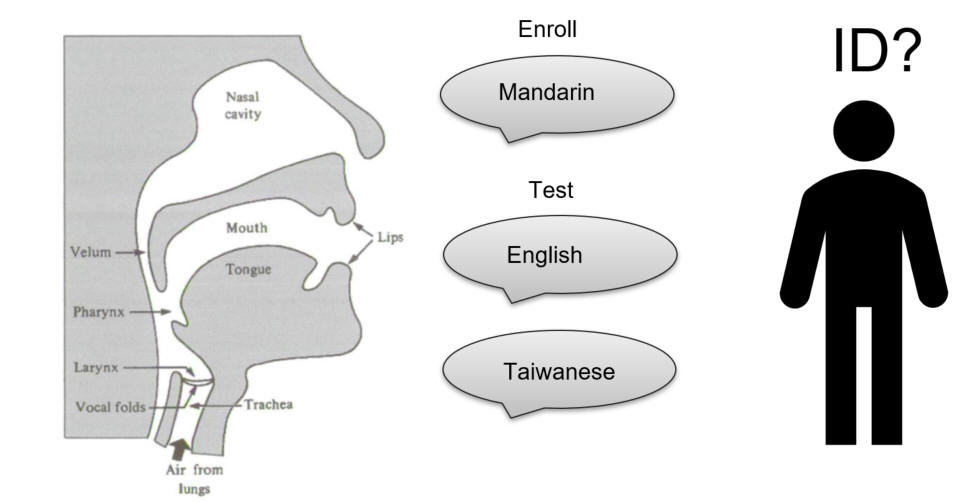
The Impact of Parroting Mode on Cross-Lingual Speaker Recognition
|
People use multiple languages in their daily lives across regions worldwide, which motivated us to investigate cross-lingual speaker recognition. In this work, we propose to collect recordings of Mandarin and Spanish, namely the Mandarin-Spanish-Speech Dataset (MSSD-40), to analyze the performance of various audio embeddings for cross-lingual speaker recognition tasks. All participants are fluent in Mandarin, but none of the participants have prior knowledge of the Spanish language. As such, they have been advised to adopt a parroting mode of Spanish speech production, wherein they simply repeat the sounds emanating from the loudspeaker. Using this approach, variations resulting from individual differences in language fluency can be reduced, enabling us to focus on the anatomical aspects of the speech production mechanism. |
|
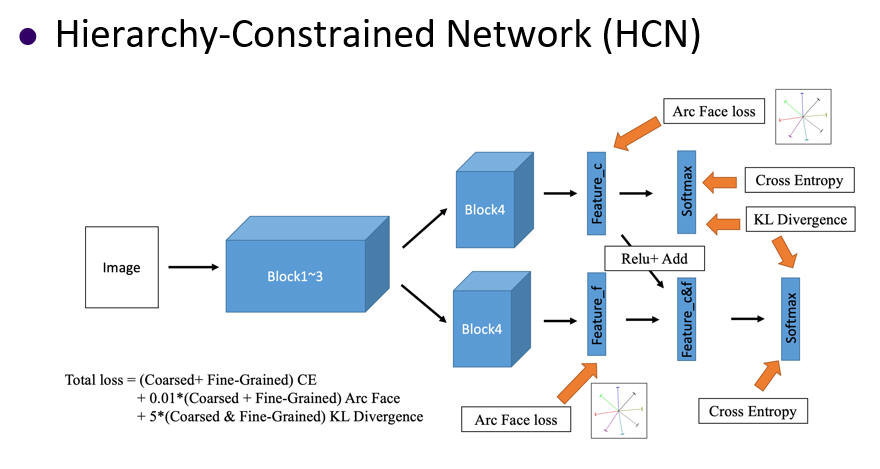
(July 2023) Deep Hierarchical Neural Networks and Its Applications
|
This research introduces a novel hierarchical model and training method called HCN (Hierarchy-constrained Network). During training, the features of the parent class are fused into the features of the child class. Additionally, two constraints are added to the objective function of the model. The first constraint considers the similarity of features between parent and child classes. If two sets of images belong to the same parent class, their features should be similar. The second constraint ensures that the predicted outputs of parent and child class categories maintain consistent relationships, such as the dog category of the child class corresponding to the animal category of the parent class, and not a truck category |
|
(Nov. 2023) Bidirectional Loss for Robust Change Detection in Satellite Images
|
Given an image pair that consists of a reference image and a query input, the objective of pixel-level change detection (CD) is to label each pixel with either 0 (no change) or 1 (change) class to locate the modified region. In this work, we evaluate the performance of deep-learning-based methods for pixelwise change detection in satellite images. Specifically, we compare three models, namely, SNUNet (CNN-based), BIT (a combination of CNN and transformer), and ChangeFormer (transformer-based) under various settings, including query preprocessing, cloud overlay, resolution change and reversal of input pair. We have identified a common discrepancy in existing approaches, i.e., their inability to cope with input in reverse order. To address this issue, two possible solutions have been proposed. The first method utilizes a data-augmentation scheme by adding reversely ordered data to the training set. The second approach modifies the loss function to incorporate bidirectional change detection during the optimization process. Both strategies have proven to work effectively, maintaining comparable performance regardless of the input order or change type. |
|
(Jan. 2023)
Detection of
Synthesized Satellite Images Using Deep Neural Networks |
The technology of generative adversarial networks (GAN) is constantly evolving, and synthesized images can no longer be accurately distinguished by the human eyes alone. GAN has been applied to the analysis of satellite images, mostly for the purpose of data augmentation. Recently, however, we have seen a twist in its usage. In information warfare, GAN has been used to create fake satellite images or modify the image content by putting fake bridges, buildings and clouds to mislead or conceal important intelligence. To address the increasing counterfeit cases in satellite images, the goal of this research is to develop algorithms that can classify fake remote sensing images robustly and efficiently. There exist many techniques to synthesize or manipulate the content of satellite images. In this paper, we focus on the case when the entire image is forged. Three satellite image synthesis methods, including ProGAN, cGAN and CycleGAN will be investigated. The effect of image pre-processing such as histogram equalization and bilateral filter will also be evaluated. Experiments show that satellite images generated by different GANs can be easily identified by individually trained models. The performance degraded when model trained with one type of GAN samples is employed to determine the originality of images synthesized with other types of GANs. Additionally, when histogram equalization is applied to the images, the detection model fails to distinguish its authenticity. A four-class universal classification model is proposed to address this issue. An overall accuracy of over 99% has been achieved even when pre-processing has been applied. |
|
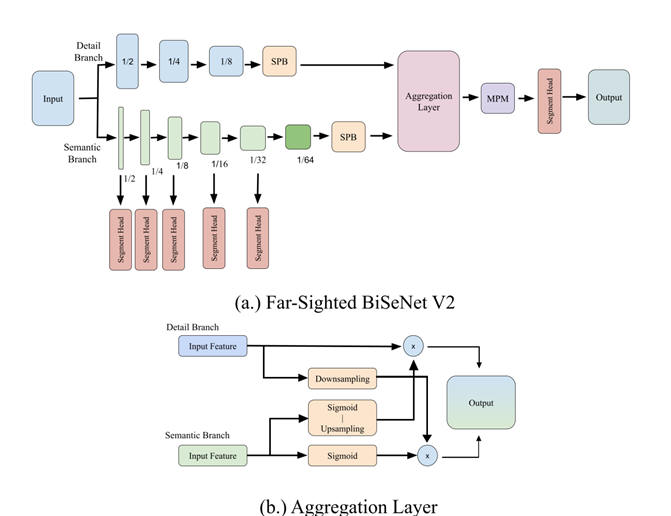
(Nov. 2021) Far-Sighted BiSeNet V2 for Real-time Semantic Segmentation
|
Real-time semantic segmentation is one of the most investigated areas in the field of computer vision. In this paper, we focus on improving the performance of BiSeNet V2 by modifying its architecture. BiSeNet V2 is a two-branch segmentation model designed to extract semantic information from high-level feature maps and detailed information from low-level feature maps. The proposed enhancement remains lightweight and real-time with two main modifications: enlarging the contextual information and breaking the constraint caused by the fixed size of convolutional kernels. Specifically, additional modules known as dilated strip pooling (DSP) and dilated mixed pooling (DMP) are appended to the original BiSeNet V2 model to form the far-sighted BiSeNet V2. The proposed dilated strip pooling block and dilated mixed pooling module are adapted from modules proposed in SPNet, with extra branches composed of dilated convolutions to provide larger receptive fields. The proposed far-sighted BiSeNet V2 improves the accuracy to 76.0% from 73.4% with an FPS of 94 on Nvidia 1080Ti. Moreover, the proposed dilated mixed pooling block achieves the same performance as that of the model with two mixed pooling modules using only 2/3 of the number of parameters. |
|
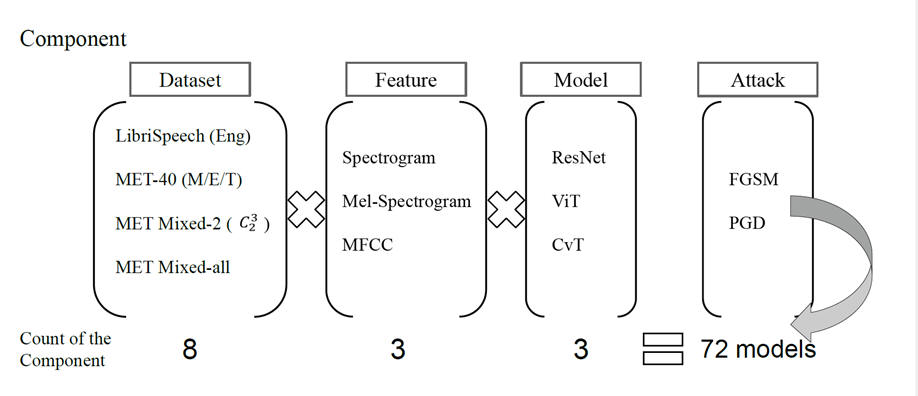
(Jan. 2022) On the Robustness of Cross-Lingual Speaker Recognition Using Transformer-Based Approaches
|
Most speaker recognition systems presume that the language for enrollment and testing is the same. Cross-lingual speaker recognition is rarely investigated. This study collected trilingual (including Mandarin, English, and Taiwanese) cross-language recordings named MET-40. A total of 40 participants (20 male, 20 female) contribute to the dataset which contains 740 minutes of audio. Spoken texts are mainly taken from elementary school textbooks, and some English texts use TIMIT. We employ ResNet, vision transformer (ViT), and convolutional vision transformer (CvT) in combination with three acoustic features, namely, spectrogram, Mel spectrogram, and Mel frequency cepstral coefficient for single, mixed and cross-language speaker recognition tasks. In the mixed-language setting, the language to be tested is included in the training set, while in the cross-language scenario the language to be tested is not used for training. Experimental results show that the highest accuracy is 97.16% for single language models. Mixture of two languages improves the performance to 99.17%. In cross-language situations, the accuracy drops significantly to 79.64%, as the spoken language is not present in the training data. When two languages are employed for training, the accuracy rose to 90.92%. In general, CvT-based models demonstrate the best stability in all cases. The robustness of the model is critical to security in practical applications. Therefore, we analyze how adversarial attacks impact different speaker identification models. The results show that although CvT-based model exhibits excellent performance, it is easily affected by the perturbation caused by the adversarial attack. The effect is less pronounced when more languages are used for training, with an average increase of 5.11% in accuracy. Finally, extra caution needs to be taken when MFCC is chosen to be the acoustic feature, as attacks can still take place without training data, and the recognition rate is reduced by 31.57% using FGSM cross-language attack. |
Other Interests:
論文發表 (Selected Publications)
Journal Papers
1. Khan S, Chen J-C, Liao W-H, Chen C-S. Towards Adversarial Robustness for Multi-Mode Data through Metric Learning. Sensors. 2023; 23(13):6173. https://doi.org/10.3390/s23136173
2. Liu, Y. W., Hsu, T. W., Chang, C. Y., Liao, W. H., & Chang, J. M. (2020). GODoc: high-throughput protein function prediction using novel k-nearest-neighbor and voting algorithms. BMC bioinformatics, 21(6), 1-16. 本人為通訊作者
3. Wu, Y. C., & Liao, W. H. (2020). Analysis of Learning Patterns and Performance—A Case Study of 3-D Modeling Lessons in the K-12 Classrooms. IEEE Access, 8, 186976-186992. 本人為通訊作者
4. Tassadaq Hussain , Sabato Marco Siniscalchi , Hsiao-Lan Sharon Wang, Yu Tsao, Salerno Valerio Mario, and Wen-Hung Liao, Ensemble Hierarchical Extreme Learning Machine for Speech Dereverberation, IEEE Transactions on Cognitive and Developmental Systems.(Nov. 2019)
5. Zhou, N., Jiang, Y., Bergquist, T.R. et al. The CAFA challenge reports improved protein function prediction and new functional annotations for hundreds of genes through experimental screens. Genome Biology 20, 244 (2019) doi:10.1186/s13059-019-1835-8.
Conference Papers
1. Sarwar Khan, Jun-Cheng Chen, Wen-Hung Liao and Chu-Song Chen (2024, Jan.), “Adversarially Robust Deepfake Detection via Adversarial Feature Similarity Learning”, 29th International Conference on Multimedia Modeling (MMM 2024) (EI)
2. Wen-Hung Liao, Shu-Yu Lin and Yi-Chieh Wu (2024, Jan.), “Evaluating the Performance of Federated Learning Across Different Training Sample Distributions”, 2024 ACM International Conference on Ubiquitous Information Management and Communication (IMCOM 2024). 本人為第一作者、通訊作者. (EI)
3. Wen-Hung Liao, Yen-Chun Ou, Po-Han Chen and Yi-Chieh Wu (2023, Dec.), “The Impact of Parroting Mode on Cross-Lingual Speaker Recognition”, 25th IEEE International Symposium on Multimedia, ISM 2023. 本人為第一作者、通訊作者(IEEE,EI)
4. Wen-Hung Liao, Hsiang-Chi Chen, Yu-Hsuan Wu (2023, Nov.), “Bidirectional Loss for Robust Change Detection in Satellite Images”, PNC 2023 Annual Conference and Joint Meetings, 本人為第一作者、通訊作者.
5. Wen-Hung Liao, Yi-San Chang, Yi-Chieh Wu (2023, Jan.), “Detection of Synthesized Satellite Images Using Deep Neural Networks”, 2023 ACM International Conference on Ubiquitous Information Management and Communication (IMCOM 2023), Seoul, Korea. 本人為第一作者、通訊作者. (EI)
6. Wen-Hung Liao, Wei-Yu Chen, Yi-Chieh Wu (2022, Aug.), “On the Robustness of Cross-Lingual Speaker Recognition Using Transformer-Based Approaches”, 26th International Conference on Pattern Recognition, Aug. 2022. 本人為通訊作者. (IEEE,EI)
7. Te-Wei Chen, Yen-Ting Huang, Wen-Hung Liao (2021, Nov). Far-Sighted BiSeNet V2 for Real-time Semantic Segmentation. The 17th IEEE International Conference on Advanced Video and Signal-based Surveillance (AVSS 2021). 本人為通訊作者. (IEEE,EI)
8. Yi-Chieh Wu, Wen-Hung Liao (2021, Nov). Intelligent Voice Assistant to Facilitate Elementary School English Learning: A Case Study Using Amazon Echo Dot. The 16th IEEE International Workshop on Multimedia Technologies for E-Learning . 本人為通訊作者. (IEEE,EI)
9. Wen-Hung Liao, Chiao-Ju Chen, Yi-Chieh Wu (2021, Jul). Investigating Viewer’s Reliance on Captions Based on Gaze Information. International Conference on Human-Computer Interaction 2021.
10. Yi-Chieh Wu, Wen-Hung Liao (2021. Jan), Toward Text-independent Cross-lingual Speaker Recognition Using English-Mandarin-Taiwanese Dataset, 25th International Conference on Pattern Recognition. (IEEE,EI)
11. Yen-Ting Huang, Wen-Hung Liao, Chen-Wei Huang (2021. Jan), Defense Mechanism Against Adversarial Attacks Using Density-based Representation of Images, 25th International Conference on Pattern Recognition. (IEEE,EI)
12. Wen-Hug Liao, Yen-Ting Huang, (2021. Jan), Investigation of DNN Model Robustness Using Heterogeneous Datasets, 25th International Conference on Pattern Recognition. (IEEE,EI).
13. Liang Jung, Wen-Hung Liao, Yi-Chieh Wu (2020. Jan), Toward Automatic Recognition of Cursive Chinese Calligraphy, International Conference on Ubiquitous Information Management and Communication.
14. Wen-Hung Liao, Yen-Ting Huang. Tzu-Shuan Huang, Yi-Chieh Wu (2019, Dec), Analyzing Social Network Data Using Deep Neural Networks: A Case Study Using Twitter Posts, 21st IEEE International Symposium on Multimedia (IEEE,EI)
15. Yen-Ting Huang;Yen-Tsung Peng;Wen-Hung Liao*, (2019. Sep), "Enhancing object detection in the dark using U-Net based restoration module", The 16-th IEEE International Conference on Advanced Video and Signal-based Surveillance, Univ. of Taipei (EI,IEEE). (*為通訊作者)
16. Tassadaq Hussain;Yu Tsao*;Hsin-Min Wang;Jia-Ching Wang;Sabato Marco Siniscalchi;Wen-Hung Liao, (2019. Sep), "Audio-Visual Speech Enhancement using Hierarchical Extreme Learning Machine", European Signal Processing Conference, Universidade da Coruña (EI). (*為通訊作者)
17. Wen-Hung Liao*;Carolyn Yu;Yi-Chieh Wu, (2019. Aug), "Construction and Optimization of Feature Descriptor Based on Dynamic Local Intensity Order Relations of Pixel Group", International Conference on Image Analysis and Recognition, University of Waterloo pp.364-375 (EI,DBLP). (*為通訊作者)