|
政治大學資科系 連耀南
|
|
1. 話說從頭
|
|
資訊技術日進千里,辛苦所學的技術常常於轉瞬間被
後起之秀淘汰,許多資深技術人員常常因為忙於專案而無暇練功,
以致基本的技術能力,尤其是程式設計能力,常常不如
後進的技術人員。資訊專業人員的安身立命之道不在於
如夸父追日般苦苦追趕這些移動目標 (moving target),而在於
充實基礎知識及專業領域知識(domain knowledge)。
利用C/C++/Java等程式語言設計一些小工具所耗的時間動輒數小時或數天,
除非是一輩子從事程式設計工作,否則資訊人在程式語言上
的設計能力將會因疏於練習而隨著時間之推移而漸漸喪失。
可是,在數位時代幾乎人人都須處理越來越多的資訊,
例如:清除一堆過期的檔案、或一堆佔用空間的影像檔、
或將一堆數位相片檔案重新命名,或從
大量的實驗資料中抽取有意義的資料等。視窗作業系統固然
越來越方便,但遇見需要大量重複某些動作時,也是非常頭疼
之事,且不說時間上的浪費,因重複太多機械性動作而
罹患腕隧道症候群的資訊從業人員更比比皆是。
資訊人很自然的會想到設計一些小程式來幫忙處理重複性
工作。
可是通常因為時間極為有限、程式設計時間遠大於所節省的時間、
且程式設計能力生疏等因素以致常常事與願違。
如同武術高手一般,如果不能「拳不離手」時時磨練拳技的話,
將漸漸的失去矯健的身手。
就以資訊相關科系教師而論,因為終日埋首於教學研究工作而
生疏於C/C++/Java等程式語言設計能力者,十有八九。
有鑑於此,資訊人有必要通曉一些可以隨手使用的程式語言,一方面
可以方便快速的協助處理重複性的工作,一方面可以經常隨手磨練。
筆者強力推薦Unix作業系統所附的各種小型程式設計語言。
|
|
Unix 自1970年代問世以來風行於世,從大大小小各種多人多工的
電腦作業系統中脫穎而出,深受系統管理者及玩家之喜愛,
其中非常重要的原因之一是:因為 Unix 具備
不錯的軟體工具及環境,可讓使用者很方便的組成各種各樣的工具,
可以大幅提高工作效率。
如同電視影集裡的馬蓋先,經常利用手邊毫不起眼的工具或物品,
運用簡單的物理原理組成非常好用的救命武器或工具。
而我們如能善用 Unix 提供的環境以及基本的工具也能利用
簡單的指令組成強大的高階指令(或應用程式),而不需
使用C/C++/Java等語言辛辛苦苦的撰寫程式。
此種程式設計環境因為都以 shell
作為最主要的語言,故俗稱為「shell programming」, 除了shell
之外,常用的程式工具為 sed, awk, ex,
perl。而用於產生網頁的工具程式 PHP也大量運用了Shell programming
的特色。
|
|
筆者使用 Unix 凡二十餘年,在電腦上寫論文、處理資料、
交換 Email、製作HTML投影片、改作業、打分數、等等
許多繁瑣的工作中,很高比例的工作均能藉由 Shell Programming
強大的能力快速解決。
雖然桌上的電腦仍然是跑微軟視窗,但最常開的軟體卻是
telent、Web browser 及一個 Unix emulator
(亦即在視窗系統上執行一個程式,創造一個虛擬的 Unix 環境)。
大部分的工作 是透過telnet 在Unix server 上完成的,
而處理個人電腦裡的檔案
也是經常使用Unix emulator 去做的。視窗系統與Unix 搭配使用,
成為最佳的工作模式。筆者的教學網頁裡數以萬計繁複的網頁,就是
憑著 vi 編輯器加上許多 shell script 獨力完成的,並不需依靠
Frontpage 或 Dreamwaver 等網頁製作軟體。
(其實,如果使用網頁製作軟體製作網頁,雖然可以手工製作非常
漂亮的網頁,可是人工成本太高了)。
在這裡,筆者先介紹幾個
小例子以展示 Unix shell script 的能力,再來談談一些經驗作為
引玉之磚。
(請注意:本文所提供的小程式只能當成「私房菜」,
做為個人的私有工具。如欲供大眾使用,則需更為嚴謹的設計。)
|
|
以下的指令將以檔名為 Image 開頭的 JPG 影像檔全部更改檔名,在
原檔名之前加上"nccu"字串。
|
|
如同一般的程式語言一般,要完成一樣事情並非只有一種方法,但多半
使用類似的演算邏輯。
而 Shell programming 可以使用的演算邏輯卻有更多的花樣。
使用者可以遵循傳統的程式設計方式設計Shell
Script, 也可以自創各種各樣另類的程式設計方式。
Shell 有很多「巧門」,如能善用
這些巧門的話,將可創出許多
的演算邏輯,可以省下許多編撰程式的時間。
一個物理學考題「 如何利用氣壓計測量一座大樓的高度?」 有一個教科書的標準答案: 「用氣壓計測出地面的氣壓, 再到頂樓測出樓頂的氣壓, 將測得的氣壓差值換算成高度」。 相傳在1922年得到 諾貝爾獎的丹麥物理學家波爾(Niels Bohr),在皇家學院 求學時,面對這個考題卻提出了幾個不同的答案: 跟上面這個故事很類似的,Shell Programming 也提供了一個非常寬廣的空間讓使用者揮灑, 運用之妙,全看使用者能發揮多大的想像力了。 以下是一個簡單的例子: 如要產生 1 至 1000 的數字, 一般人很自然的想到用迴圈(loop)的方法, 使用 C/C++/Java 等程式語言撰寫一個程式, 經過編譯與執行,得到一支程式。 以下是利用迴圈方式所寫的一個 C 程式:
如果你常用 cut 這個指令的話,這個方法只需構思數分鐘,再花個數秒鐘 直接從鍵盤鍵入指令,就可輕易得到結果。 如果你對 awk 熟的話,下面這個方法更為簡單:
|
|
如果對 awk 或特定工具程式不熟也無傷大雅,反正條條大路通羅馬,
前面兩種方式也可做到同樣的事。
|
|
以上小例子看似簡單,但它可是一種另類的程式,完全不用迴圈。
讀者可發揮無限的想像力發掘更多的巧門。
對於一般非專職程式設計師的使用者而言,使用
head、cat、cut 等這些常用指令遠比寫一個 C/C++/Java
程式更為熟練,所花的心力通常微不足道。
常常只需花個數分鐘時間就可以寫個shell script
幫忙處理很多瑣事,可節省不少時間。
由於所費時間不多,甚至不需刻意保存所設計的script,
用過一次就丟掉,下次有需要時,重新再寫一次還
比花時間去找留存的shell script還更省事,
只有時常會用到的script才有留存供重複使用的價值。
再者,小小的程式,要瞭解非常容易,很可能
比閱讀程式的註解還容易,所以很多情況下連註解都是
多餘的了。當然,如果要設計一個大型的程式,還是必要
規規矩矩的按部就班去撰寫程式以及加入註解。
|
|
要具備善用 Unix 的功力的話,傳統的程式訓練是不夠的,
必須對Unix 的環境及各種工具程式的特性有相當深入的瞭解,
尤其是對於用來組合各種工具程式的程式─shell,更需有透徹的瞭解。
|
|
2. Shell Programming 之優缺點
|
|
任何一種程式語言都有其最適用的情況及其罩門,Unix
Shell Programming 也難逃此宿命。它有幾項優點:
|
1. Script 都是純文字檔,不被特定軟體綁住
| 2. Shell script 不需編譯即可使用,非常容易移植到不同的 Unix 環境
下執行
| 3. 適合用於開發以字串處理及檔案管理為主的簡易小軟體
| 4. 因開發 shell script 耗時極短,玩家可隨時根據自己的需求動手開發或更改
| |
|---|
|
1. Script 都是純文字檔,不被特定軟體綁住
|
|
大部分的檔案都是以文字檔存放,這是非常開放的系統,檔案之間的分享
非常方便,一個程式所產生的檔案很容易為其他程式使用,一個程式
在使用其他程式所產生的檔案時,也不需知道是何種程式所產生的。
比起現行個人電腦視窗系統上的各種使用專屬格式的應用程式而言,
方便很多。
|
|
2. Shell script 不需編譯即可使用,非常容易移植到不同的 Unix
環境下執行
|
|
shell/awk/sed/ex/perl script 都是純文字檔,也不需 編譯即可使用,非常方便,從一個系統移植到另一系統時,直接 搬過去即可,雖然可能要更動某些系統設定,但是因為不需重新 編譯,可省下不少麻煩。 幸運的是,現在已經有許多 Unix Emulator,例如 UWIN 及 cygwin, 可以在微軟視窗系統下利用 shell script 處理 PC 的檔案。 |
|
3. 適合用於開發以字串處理及檔案管理為主的簡易小軟體
|
|
Shell script 處理字串的能力很強,特別受系統管理員的喜歡。 此外,很多script 長度很短,也很簡單,是所謂的 "little programming"。 當設計一個專供個人使用的 script時, 幾乎不需另外寫使用手冊,直接看script 就可以瞭解其用法。 要維護也很簡單,不需撰寫複雜的維護手冊或設計手冊。 因此,大部分的情況下,撰寫 shell script 所花的時間很短,數分鐘而已。 當然,如果是要寫一個比較複雜或供公眾使用的 script 時,這些囉唆的 額外工作還是要按部就班去做的,省不了多少時間。 |
|
4. 因開發 shell script 耗時極短,玩家可隨時根據自己的需求動手開發或更改
|
|
如果是專供個人使用的 Script,當然可以隨意的根據自己的需要設計, 反之,如果是使用他人提供的程式時,不但無法完全符合個人需求, 使用者還須花時間去尋找適用程式,更須花時間去 K 使用手冊。 很多時候,還不如自己寫個 shell script,不但更省時間, 也更符合自己的需求,更可以隨著需求的變動而隨時更改程式。 |
|
缺點當然是免不了:
|
1. 執行效率較差
| 2. 力有未逮之時
| 3. 漏洞難免
| |
|---|
|
1. 執行效率較差
|
|
Shell 因為是用 Interpreter 而且是用間接的方式達到目的 (除了程序控制的指令之外,大部分都是叫用 UNIX 的既有程式來執行), 其執行效率不佳。例如,前面所舉的數字產生器,如果是用head, cat, cut 去組合成的話,因為這三個指令是三個不同的程式,呼叫起來要耗費 相當長的時間, 比傳統的 C/C++/Java 的迴圈方式慢很多。 可是,話說回來,終端機前的使用者對於0.001 秒與數秒的反應時間 根本不會察覺其差異,即使可以察覺差異,也不太計較。 反而是構思與程式設計所花時間較長, shell script 的設計通常可以省下數小時甚至數天的設計時間, 那差別可大了。如果程式的執行時間只長了數秒鐘,但卻節省了數小時 的設計時間,對於個人使用的小程式而言,這筆買賣太划算了。 |
|
2. 力有未逮之時
|
|
Shell 畢竟不是傳統的 general purpose 的程式語言,
有些事是做不到或很難做的,例如,在shell裡進行數學運算或陣列處理時
就很麻煩,所以不可能作為大型軟體
的主要開發語言。所幸,後來發明的 perl 程式語言融合了
shell script 及傳統程式語言的優點,其能力已經不下於傳統的
程式語言,現在很多大型公用軟體都是使用perl去撰寫的。
此外,shell script 可以很方便的處理文字檔,但對於非文字檔 及多媒體檔等就很不方便,例如處理微軟的 Winword 所產生的 doc 檔,那就無能為力了。在處理多媒體檔案時,常需用到硬體的 驅動程式,而不幸的是,系統不一定有提供驅動程式的介面。 如果你希望寫一個需要大量數學運算的程式,應該不會選擇使用 shell programming 吧? |
|
3. 漏洞難免
|
|
由於設計給個人用的程式不免為了省時省事而忽略了很多 意外的處理,使用不慎時會有嚴重後果,必須非常小心,尤其是 當script 有涉及檔案的更動時,更須特別小心。 話說回來,如果設計用完即丟的小程式時也要將所有意外情況都考慮清楚, 那也省不了多少設計時間,也就失去了原有 little programming 的立意。 有得必有失,得失之取捨,得由使用者視情況來決定。 |
|
3. 學習 Unix Shell Programming 之方法
|
1. 熟悉 Unix 上各種基本指令及小型工具程式
| 2. 盡量熟悉 Regular Expression
| 3. 熟悉各種特殊符號及其用法
| 4. 熟悉 Unix 上各種系統檔案的路徑
| 5. 熟悉 Unix 基本精神
| 6. 熟悉 Unix 程式設計的一些習慣,並盡量配合
| 7. 多練習,多使用
| 8. 盡快學會一個 Unix 上具有regular expression的編輯器
| |
|---|
|
1. 熟悉 Unix 上各種基本指令及小型工具程式
|
|
市面上有很多書,網路上有很多教學網站可以上去學習,筆者的教學網站 (www.cs.nccu.edu.tw/~lien/UNIX.htm) 也有一些資料,如今的資訊專業人員可以很輕易的找出來。 有用的小型工具程式 (little programming language) 包括 shell, sed, awk, ex 等。最有名的書店當為 O'Reilly 這家書店, http://www.oreilly.com/, 出了很多相關的書,他們甚至將較早期 出版的書的電子版放上網路讓大家免費下載。 此外,perl 是一個更高級的programming language, 很多要 利用好幾個程式工具合作才能完成的事,都可以輕易的在perl中解決。 但是,因為perl 包含了很多 shell/awk/sed 的功能,也比較繁瑣, 最好等歷練過shell/sed/awk/ex 這些之後才來學 perl 會比較 容易上手。最後,如果要製作含有 CGI 的網頁時,學學PHP 等專為CGI 設計的語言,也是很重要的。 |
|
2. 盡量熟悉 Regular Expression
|
|
Regular Expression (例如檔案名稱所用的萬用字元) 是 shell programming 之所以非常強大的關鍵之一,在 awk/sed/ex/vi 都有相容的 regular expression,而perl提供的regular expression 能力更為出色,使用者能用很簡單的 expression 表達豐富的字串型態。 使用者務必盡早熟習,對於受過正統資科訓練的人而言,熟習regular expression 並非難事。 |
|
3. 熟悉各種特殊符號及其用法
|
|
每一個工具程式都會有一些特殊符號,例如regular expression 就有很多符號, 當一個script 是叫用多個 工具程式時,這些特殊符號必須使用層層的escape符號來配合。 Shell script 的內容會變得非常奇怪,難以解讀。使用者必須有 能力克服這個困難才能盡情發揮shell script 的功能。 在設計shell script 的過程中,最常碰到的問題之一,是來自於特殊符號之處理不當。 |
|
4. 熟悉 Unix 上各種系統檔案的路徑
|
|
類似微軟視窗系統裡的登錄檔或暫存檔,Unix 裡面也有。 使用者最好瞭解這些系統檔案的存放區, 例如:/bin, /tmp., /etc. /usr/mail, /usr/bin 等, 至少我們可以加以運用,在我們舉出來的實例中, 就有利用到spell 所用的字典檔案來設計自己的script的。 所幸,這些路徑比起微軟視窗系統的登錄檔簡單許多,不難記住。 |
|
5. 熟悉 Unix 基本精神
|
|
例如 directory 及 device driver 在Unix中均視為檔案,其管理方式 就像管理檔案差不多。例如:使用者的螢幕在 Unix 中是以一個檔案來代表,我們可以將一個訊息寫到這個檔案,就成了簡單的 Instant Message 功能。 |
|
6. 熟悉 Unix 程式設計的一些習慣,並盡量配合
|
|
例如: 而所有產生的資料盡量由 STDOUT 輸出,以方便組合成其他指令。 如果該指令可用來用在 "|" 「管線」之中的話, 其資料盡量由 STDIN 輸入,這應由使用者自己拿捏。 |
|
7. 多練習,多使用
|
|
如同其他的程式語言一樣,學習一個程式語言的最好方式是多練習寫程式。 對於很多程式語言而言,必須投資很長的時間才能順利寫出「實用」 的程式,可是並非人人有那麼多的時間投入練習。因此,很多人離開學校之後, 除非工作需要,否則很難精通新的程式語言。例如,很多資訊科系的資深教師, 如果不是教學需要,大部分不會精通 Object-Oriented 程式語言 。 Shell programming 有一個很有利的優勢:因為初學者很快就可以寫出 對自己很實用的小程式。最簡單的起步,即是將所要重複下的指令儲存 在一個檔案內,然後當成shell script 來執行,馬上可以節省很多鍵入指令的時間,增加個人生產力。 有心學shell programming 的人,很快就可以設計一些小程式來幫助 自己節省時間。只要能節省時間,就有強烈誘因盡可能設計小程式來取代 人工作業,如此,就不斷的有機會練習。隨著時間推移,就可以一面節省時間, 一面練功,不知不覺中,功力就不斷的增加。 |
|
8. 盡快學會一個 Unix 上具有regular expression的編輯器
|
|
Unix 上的編輯器當然不如視窗系統上的編輯器好用,但既然要使用Unix,
總要學一個方便好用的編輯器。
要將一個非視窗系統上的編輯器使用到「如臂使指」般
達到touch typing 的境界需要非常長的時間,
而在現今視窗系統的編輯器如此好用的情況下,大部分的人非常不願花長時間
學習一個Unix 上的編輯器,因而使用編輯器之能力反而成為學習shell
programming 的最大障礙。
有一個簡單的方法繞過這個問題:使用視窗系統的編輯器鍵入script 然後移植到Unix 系統上。假設使用者是在視窗系統上使用一個具有剪貼功能 的 Telnet 軟體連接到一個Unix 伺服器上,使用者先用 Notepad 編輯器編輯 script,然後剪到剪貼簿,然後在Telent 視窗上鍵入 "cat > scriptfile", 之後利用 Telent 上的剪貼功能將剪貼簿的內容貼上去,最後鍵入"^D", 完成"cat"指令的執行。如此,script 就被貼入 "scriptfile"這個檔案。 以上的方法是一個不得已的,讀者最好還是要學一個編輯器。 對於編輯器,每個人都有自己的偏好,讀者可自行挑選。 筆者一向使用"vi",因為幾乎所有版本的Unix 都有內建,而且vi 具有與 其他工具程式類似的 regular expression 之處理能力,以及具有programming 性質的指令集, 使得功能非常強大, 而且可以不斷的練習 regular expression,有助於shell programming 的練習。 |
|
4. Shell Script 設計小秘訣
|
1. 定期備份,隨時備份要更改的檔案
| 2. 慎重選用適當的工具程式
| 3. 盡量自動化
| 4. 不要勉強自動化
| 5. 適時搭配 PC 視窗系統
| |
|---|
|
1. 定期備份,隨時備份要更改的檔案
|
|
最重要的是系統要定期備份, 越方便能力越強的系統,其破壞力也越強大。 例如: 如果某個使用者下一個如下的指令要清除一些檔案:
|
|
2. 慎重選用適當的工具程式
|
|
雖然是條條道路通羅馬,但是各種工具程式各有其特性, 使用者最好瞭解各種工具程式的特性,再據以挑選適當的工具來用。 選用適當的工具會讓你事半功倍,否則可能是自找麻煩。 |
|
3. 盡量自動化
|
|
只要能自動化就自動化(能偷懶就偷懶),讓shell 負責執行繁瑣的重複性工作。
|
|
4. 不要勉強自動化
|
|
不要為自動化而自動化,有時候直接用手去做反而更快。
我們所舉的例子中,就有要求使用者進入vi 去做事的, 並非全部交由shell自動去做。 不過,為了磨練shell programming 的技巧,有時候 難免多花點時間找點苦頭吃,也是不錯的。 |
|
5. 適時搭配 PC 視窗系統
|
|
如果搭配視窗系統去作比較方便時,那就不要硬在Unix上作。 視窗系統絕對有其優點,跟 shell programming 搭配使用 ,將可發揮 相輔相成之功效。 |
|
5. 一些實用的 Shell Script 實例
|
|
以下所舉之範例均省略掉必要的意外處理,使用者在使用時應注意到這個問題,
尤其是在更動檔案時,避免對檔案造成意外的更動。
|
|
這裡的 shell script 分為兩種,一種是沒有變數,可以直接在 command line
直接使用的,所有參數都是直接給定的,我們歸類為 "Command"。
另一種則是含有 $1, $2, 等變數,必須存成檔案做成可以重複使用的指令,
所需的 $1, $2, 等參數由使用者在叫用該 script 時才給定,
我們將這類 script 歸類為 "Script"。
儲存script 的檔案的檔名即為 shell 呼叫時的指令名稱。
在沒有重複或與 shell 內建指令同名的條件下,讀者可以自己任意命名。
在「用法」 裡有說明Script的叫用方式,但有些 script 並沒有標明「用法」,
讀者可以從 script 中輕易的看出如何使用,自行製作成指令。
|
|
5.1 簡單的 script
|
| 功能 | 抽取檔案中含有某字串的"行",並列出行數
| 用法 | gn [options] <pattern> <filename1> <filename2> ...
| | grep -n $*
| 解釋 |
可以用來檢視哪些檔案含有某一字串,並列出所在行數。
這個 script 很單純的將使用者所下的grep 指令加上 -n 選項而已。
因為很多其他的script
會需要知道某些字串在檔案中的位置,使用頻率很高,
建議製作成指令以便重複使用,省點打鍵盤的功夫。
| |
|---|
| 功能 | 查看信箱內最後100行資訊
| | tail -100 /usr/mail/yourname
| 解釋 | 假設系統將各人的信箱放在 /usr/mail/yourname
| 這個指令將信箱中的最後100行印出來, 可用來檢查是否有新信件進來。 註 | 現在的 email 經常有不同的中文編碼方式,或帶有非純文字
的附加檔,如有這種情況,看到的可能是亂碼。這個 script
對中文的使用者而言,現在幾乎是無用武之地了。
| |
|---|
| 功能 | 將檔案變成 double space
| | sed G <filename>
| 解釋 | G 是 sed 的指令,其作用是將 buffer 的內容加在輸入檔的
每一行後面,但因為buffer內的初始值是空的,其效果等於在每一行
文字後面加上一個空行。
| 註 |
請注意:G 是 sed 內的一個一般性指令,並非特意為double space的功能
所設計的。
| |
|---|
| 功能 | 計算檔案的行數
| |
|
解釋 |
wc 這個指令會列出一個檔案的行數、字數、及字元數,其格式
隨系統而不同,使用者必須依據實際情況調整。
在很多script中都會用到檔案的行數作為參數,所以有必要
設計一個指令將所需要的資訊從wc 這個指令所輸出的一堆資訊中提出來,
提供給其他指令使用。
| 註 |
各個不同的 Unix 系統對於 wc 這個指令可能各有不同的輸出格式,使用者
當根據實際情況設計這個script。
| |
|---|
| 功能 | 產生從1開始的數目序列
| 用法 | count <number>
| Script m5a
|
|
Script m5b |
shell 支援數學運算的能力很弱,但
如果你的系統有支援 $(( ... )) 這種運算的話,這個script
可以寫得簡單一些。
|
| 解釋 m6 |
假設 <longfile> 是一個超過 $1 行數的檔案,
|
| head -$1 <longfile> | awk "{print NR}"
| | head -$1 <longfile> | perl -ne 'print "$.\n"'
| 註 | 上面這些另類檔案之成功與否,依賴著 longfile 的大小,
是個漏洞,因此並非是嚴謹的程式,不能拿來作為正式的應用程式使用,
本文舉這個例子,只是用來展示「另類」的運算邏輯之用。
| |
|---|

| 功能 | 產生一個區間的數目序列
| 用法 | numberseq <begin-number> <end-number>
| Script m5b
|
|
|
|---|
| 功能 | 產生一個區間的等加序列
| 用法 | numberseq <begin-number> <end-number> <skip-number>
| Script m5c
|
|
Script m5d
|
|
|
|---|
|
Generate 26 English Characters
|
Take a file that has many English words
| Use Vi to split words into characters
| Use spell split them into a line per character
| use sort -u to sort it
| edit the file
| use tr to obtian upper or lower case
| |
|---|
| 功能 | 即時訊息 (Instant Message)
| | echo "Hello!" > /dev/ttyxx
| | cat filename > /dev/ttyxx
| 解釋 m9,m10 | Command m9 將"Hello!"字串送到終端機 ttyxx 上,
Command m10 將檔案 <filename> 的內容送到終端機 ttyxx 上,
這就是一種instant message(通訊範圍侷限於同一系統的不同使用者,
而非網路上不同系統上的使用者)。
| 終端機在Unix 裡被視為一個檔案,在早期其權限通常是對所有使用者 開放的,(當然使用者可以關閉權限), 任何使用者可以將任何資訊送進這些檔案,其效果等於將資訊展現 在那個終端機上。 註 | '/dev/ttyxx'是代表終端機的檔案,
使用者可以利用 who 這個指令,找出收訊者的終端機
編號。uid 後面即是 terminal id, 鍵入 tty 指令,即可得知系統
如何將你的終端機命名。
| 此外,各個系統為終端機檔案命名的方式各有不同,也有如此方式的: "/dev/pts/15",使用者可以從指令 tty 的輸出結果可以知道 你的系統如何為終端機檔案命名。 | cat < /dev/ttyxx
| 解釋 m11 |
既然別人的終端機可以寫入,那當然也可以讀出,這個指令
可以讓人偷窺他人在終端機上所敲的任何鍵!!
不過,別慌,系統的初始設定應該會將他人讀這個檔案的權限關閉,
只有 super user 可以讀得到這個檔案。
| |
|---|
| 功能 | 搜尋檔案
| | find $HOME -name <pattern>
| | find . -name <pattern>
| 解釋 |
Script m12 從 $HOME 開始往下搜尋名為 <pattern> 的檔案,
| Script m13 從現在的工作目錄開始往下搜尋名為 <pattern> 的檔案。 <pattern>裡可以含有萬用字元。 但必須用 "" 保護起來。 |
|---|
| 功能 | 搜尋最近一天內產生的檔案
| |
|
|---|
| 功能 | 刪除空檔案
| |
|
註 | find 這個指令可以順便將找到的檔案加以處理,其指令是帶在
-exec 選項中,筆者不建議執行如此危險的指令,萬一下錯指令,
將會萬劫不復。
筆者建議先產生要處理的檔案,經過人工檢視,沒問題之後,
再利用這個含有檔名的檔案轉成另外一個shell script,
再拿這個 script 去執行。
| |
|---|
| 功能 | 分割檔案
| |
split <filename>
| 解釋 | 將一個檔案分成數個檔案
| |
split -b 1m <filename>
| 解釋 | 將一個檔案分成數個 1mb 的檔案
| |
|---|
|
5.2 為一群檔案更改檔名
|
| 功能 | 為一群檔案更改檔名
| |
|
解釋 | 這個 script 將以檔名為 Image 開頭的 JPG 影像檔全部更改檔名,在
原檔名之前加上"nccu"字串。
當然,如果嫌檔名太長的話,可以加幾個指令,可以做得更好。
| 如果要將數位相機照得的一堆影像檔改個較有意義的檔名時, 這非常好用。 此外,為一群檔案更改檔名這件事,也可以很方便的使用find 的指令,利用其 "exec" 功能來簡單的做到,但是這樣做非常危險, 一有錯誤就可能導致災難性的後果,因此不建議大家使用這個方式, 寧可用比較間接,但比較安全的作法。在寫完script 之後,先檢查 清楚,測試一下,再真正執行你要做的工作。 |
|---|
| 功能 | 為一群檔案更改檔名
| |
|
解釋 |
|
這個 script 比 changename1 有彈性 (flexible), 它先產生如下的 script 初稿
讀者可自行將vi 取代為任何自己所喜歡的編輯器。 這個script的功能與上個script 一樣,但更為安全,因為可以仔細檢查 執行步驟。 |
|---|
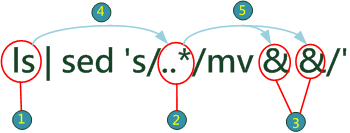
| 功能 | 將現目錄下所有 *.txt 檔案之檔名改成 *.csv
| | |
解釋 |
`command` 相當於很多其他程式語言裡的 eval(command),亦即, 當 shell 執行到含有`command`這一行指令時,先將command 當作一個指令執行,然後將所得結果置換於原位置, 再執行那一行被修改過的指令。而執行
現在很多實驗室的自動測量儀器都會將測量數據以 ASICC 文字檔方式存在內部的檔案中,一個實驗作下來,可能有數十甚至 數百個數據檔案,使用者想用 Excel 等工具看這些數據時,如果能將 檔案型態從 .txt 檔改成 .csv 檔,那可省下大量的時間。當然,必須 先利用shell srcript 將分隔符號改成逗點。 |
|
|
|
| |||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|



| 功能 | 將現目錄下所有 nccu.* 檔案之檔名改成 NCCU.*
| |
這個script 的功能與上個script的功能類似,但所更改的卻是 "." 之前的名字。
|
|---|
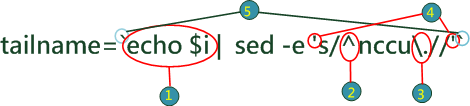
| 功能 | 將目前目錄下的所有檔案名改成小寫檔名
| | |
解釋 |
|
|
|---|

|
5.3 轉檔程式
|
| 功能 | 將 DOS 文字檔轉成 UNIX 文字檔
| 用法 | dos2unix <filename>
| Script c1
|
|
解釋 |
這個 script 是利用 ex 裡面的編輯指令來解決 DOS/Windows .txt 檔案與
Unix 文字檔之間格式不同的問題,
在DOS 的 .txt 檔案中,行與行之間用兩個ASCII符號 (十進位010, 013)
作為間隔,而 Unix 中只需用一個間隔符號,因此這個script 利用 ex
除掉一個。
| 在script 中,^M 是一個控制字元,請 不要誤解成 '^' 及 'M' 兩個字元。 在vi 中可用 此外,shell 將"<<%" 與 "%" 兩個符號之間的 text 送給 ex 作為使用者之 鍵盤輸入。再者,由於 $ 這個字元在 shell 中是特殊字元,必須 加上escape字元才行,其未加 escape 字元的原始編輯指令如下:
|
|---|
| 功能 | 將下列字串
| ||
|---|---|---|---|
| |
| ||
| |
| ||
| 解釋 |
| 功能 | 將前兩欄資料(以空白作間隔)互換順序
| |
|
解釋
| 注意 \( \) \1 \2 在 ex/sed 裡的意義
| | |
| |
解釋 | 注意 ' ' 這對引號在這裡的用處,它可以避免shell 將$1, $2
當成變數。讀者應盡可能熟悉 ' ', " ", 及 ` ` 這幾對引號的用法。
| |
|---|
| 功能 | 將一個檔案轉成兩欄格式
| | pr -t -l66 -w80 -2 <filename>
| 註 |
現在有 Winword 作為文件的編輯程式,在Unix將文件做
兩欄式的編排之需求已經大不如前。
| |
|---|
|
5.4 檔案片段之擷取
|
| 功能 | 檔案片段之截取 (extract a block of lines)
| 用法 | bcut <beginline> <endline> <filename>
| | v1 sed -n -e "$1,$2p" $3
| 解釋 | 使用 Script bcut 時,使用者要提供開始及結束之行數,sed
會將檔案 $3 讀進來,將 $1 到 $2 之間的「行」印出來,sed
會繼續執行直到 $3 全部讀完才停止。
| Script bcut | v2
|
解釋 | 同 v1,但比 v1 快,當sed 將輸入檔案讀入時,
讀到 <endline> 時就停止,而 v1 則會一直讀到最後一行。
| | v3 awk '/<beginline>/,/<endline>/' <filename>
| 解釋 | 使用這個指令時使用者不是輸入行數,而是
輸入含有 <beginline> 字串的行及
含有 <endline> 字串的行。
| |
|---|
| 功能 | 檔案片段之刪除 (delete a block of lines)
| 用法 | brm <beginline> <endline> <filename>
| | |
解釋 |
這個script 先製作一個編輯指令檔,再利用它來編輯原文,
備份留在 tmp.o
| |
|---|
| 功能 | 刪除含有特定字串的行
| | |
|
|---|
| 功能 | delete blank lines from a file and output to STDOUT
| |
|
解釋 | 注意 -v 在 egrep 裡的作用,而 '^$' 在
regular expression 中代表空行
| |
|---|
| 功能 | 檔案片段之代換 (replace a block of lines)
| 用法 | brp <beginline> <endline> <filename> <filename>
| | |
|
|---|
|
5.5 簡單的統計運算
|
| 功能 | 計算某欄的平均值
| 用法 |
avg <column> <filename>
| | |
|
|---|
| 功能 | 計算某欄的最大(小)值
| 用法 | max <column> <filename>
| | |
|
|---|
|
5.6 資料擷取
|
|
5.6.1 基本模式
|
|
我們常常需要處理多欄文字檔,例如大量的實驗數據,而
常常需要根據某欄位的值作為條件抽出該列,甚至該列的某些欄值。
就像關聯式的資料庫裡的 Selection 加 Projection 的動作。
可惜 grep 並不能指定比對的欄位,只能利用 awk 這類工具來處理。
例如:
|
|
|
|
而下面這個 script 則先產生一個 awk script ,
再用這個 awk script 來處理輸入資料,結果相同。
|
echo '$2 == 30 {print $4, $1}' > awk.script
awk -f awk.script inputfile
|
|---|
|
5.6.2 可任意指定比對的欄位
|
|
如果使用者希望能彈性的指定比對的欄位以及印出的欄位,
就需要比較高明的 script
Take the first argument as the column position, the
second as the given pattern, and the third
as input file to filter out those lines
whose value at the given column matches to the
given pattern.
|
|
|
|
|
為增加實用性,可增加指定 field delimiter 的 option
|
|
5.6.3 可任意指定比對的欄位及輸出欄位
|
|
Same as previous version, but with the 4th and
after arguments as the columns to be printed
It can be viewed as a Selction after a Projection operations in Relational database.
|
|
|
|
Script 1 (使用迴圈打造 Ex Script,再用 Ex script 編輯 Awk Script)
|
|
|
|---|
|
Script 2 (使用迴圈打造一個變數,再展開此變數加進 Awk Script)
|
|
| ||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
 |
|
|
Script 3 (不用迴圈)
|
|
|
|---|
|
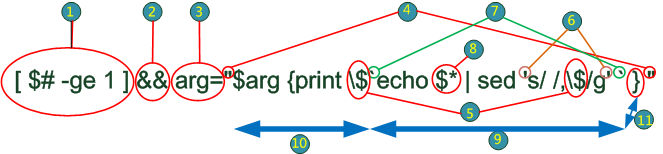
第四行之解釋 (以 grepdom 2 30 input 4 2 3 為例)
|
 |
|---|
| 1 | 檢查是否有指定輸出欄位 | 7 | 抓出 echo $* | sed 's/ /,$/g' 的結果
| 2
| 若有指定輸出欄位,則執行 3
| 8
| 全部的輸入變數,以空白隔開,得到 4 2 3
| 3
| 將後面的字串放進 arg
| 9
| 以 sed 將 $* 中的空白全部改成 ,$,得到 4,$2,$3
| 4
| 利用 " " 將字串包起來
| 10
| 字串 $2 ~ /30/ {print $
| 5
| 保留 $ 字元,避免被當成變數
| 11
| 字串 }
| 6
| 利用 ' ' 將送給 sed 的指令包起來 | 's/ /,$/g' 9-11
| $2 ~ /30/ {print $4,$2,$3}
| |
|---|
|
Script 4 (不用迴圈)
|
|
|
|---|
|
Script 5 (最簡版)
|
1 arg="\$$1~/$2/"
2 shift 2 #捨棄前面二個參數,剩下輸出欄位參數
3 [ $# -ge 1 ] && arg="$arg {print \$`echo $* | sed 's/ /,\$/g'`}"
4 cat | awk "$arg"
|
|---|
|
5.7 英文拼字工具
|
| 功能 | 找一個英文字
| 用法 (例) | wordhelp con v en t
| ( e.g. looking for the word "convenient") | |
解釋 | 很多Unix 系統都有個spell的指令,這個指令一定會用到
一個字典,其中含有大部分的英文單字,我們可以運用
這個檔案來做很多跟字典有關的工作。
使用者可以嘗試找找這個檔案 /usr/lib/dict/all。
| wordhelp 這個script 是筆者最常用的script,寫英文文章時幫助非常大。 我們對一個英文字的拼法不熟時,查一般的字典也無從下手, 可能要試很多次,將一部字典翻來覆去才能找到要查的字。 即使在網路上找英文字,當不知道如何拼字時,也是無輒。 wordhelp 這個 script 可讓使用者輸入一個英文字的某些片段,就可以將含有 這些片段的英文字列出來,而同時含有這些片段的英文單字 屈指可數,很容易就可挑出自己想找的單字。 請注意,這個Script 出現了一個罕見的 shift 指令,這是 shell 裡一個重要的指令,可以將使用者在command line 所下的參數做個變動, 將 $1 捨棄,而將後面的 $2, $3, $4 等往前移動,如此,在script 中就可以將原代表所有參數的變數符號"$*"用來代表 $2, $3, $4 等參數。當然,shift -n 可以"移動"n個參數。 |
|---|
| 功能 | grep with multiple patterns
| 用法 | mgrep <pat1> <pat2> <pat3> ...
| |
|
解釋 |
Script s2 會將STDIN含有數個指定字串的「行」抓出來,
使用者可輕易更改這個script,讓他可以grep 更多的pattern。
下面的 spellcorrect 會用到這個關鍵的 script。
| |
|---|
| 功能 | Spelling Corrector
| 用法 | spellcorrect <filename>
| |
|
解釋 |
這個script 先將輸入的檔案利用spell找出字典沒有的字,
其次將使用者的專有字剔除,
然後將剩下的錯字製造出一個編輯指令檔,再叫出vi 來讓使用者
將該檔案編輯成一個可以更正錯字的編輯指令檔,最後
叫出ex 編輯器利用此編輯指令檔將原文裡的錯字改掉。
當然,讀者可自行將vi 取代為自己喜歡的編輯器。
| 在Unix 上寫英文文章時,這個script 可以幫忙更改錯字, 省下很多麻煩的編輯動作,非常有用。  問題 | 利用這個script時,有時候要注意編輯指令檔的正確性,
萬一發生錯誤時,可能會破壞原檔案,改到不該改的字。
例如,如果文章裡有個 "th"的字被挑出來,使用者如果
將這個指令
1,$s/th/th/g
改成
1,$s/th/the/g
的話,後果將會很嚴重。
| 此外,ex 是一個 atomic 的程式, (do all or do nothing), 如果其中有一個編輯指令失敗,最後的 w 將不會作用,導致 執行失敗。 例如,下面的編輯指令會失敗。
|
|---|
|
5.8 HTML 相關程式
|
| 功能 | 產生一個色表
| |
|
解釋 |
本 script 會產生一段 HTML 碼,這段 HTML 碼在瀏覽器上會
顯示一個色表,裡面有各種顏色及其對應的 RGB 碼,
使用者可輕易改寫,增加更多的顏色。
| 結果
|
|
註 | 這個 Script 裡 R,G,B 的參數如果都改為 00, 33, 66,
99, CC, FF,就可以產生一個展示216安全網頁顏色的 HTML 檔
| |
|---|
| 功能 | filtering out words: is, this, a
| |
sed "s/this//;s/is//;s/a//;s/ *//g"
| 解釋
|
| Input: this is a dumb question Desired Output: dumb question if you want to filter 'is' but not "isn't", that wouldn't work; you could still use sed, but I think I'd use perl so that I don't have to code 3 sed substitutions for every word: | |
| |
| |
|
|---|