An Adaptive Hybrid Shared Memory Architecture
演講摘要
演講詳細內容 相關資料
相關網站
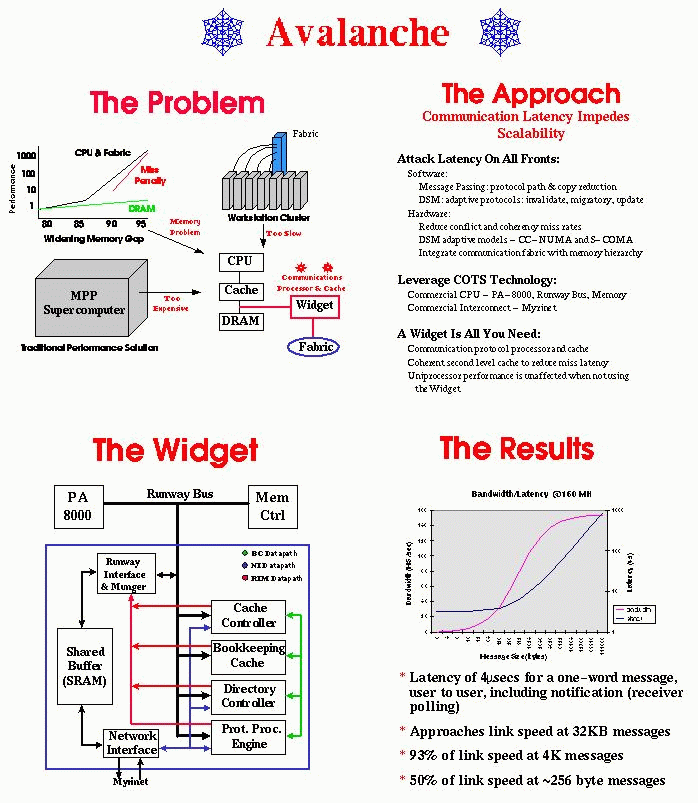
Avalanche
Avalanche主要是雪崩的意思,除了配合UTAH的特色,這個名字跟這個project蠻有關係的,scalable就是說你可以一直一直的擴張而不會有侷限,從剛開始就是從小雪片,加上一個石頭就變成一個雪球,然後雪球堆堆堆就變成雪崩,所以它可以越堆越大,關於作parallel
processor也是這樣,不是說設計一個機器最多只有十六個CPU,而是希望說能六十四個,甚至是幾千個,上萬個CPU,所以這個名字大概是這樣。
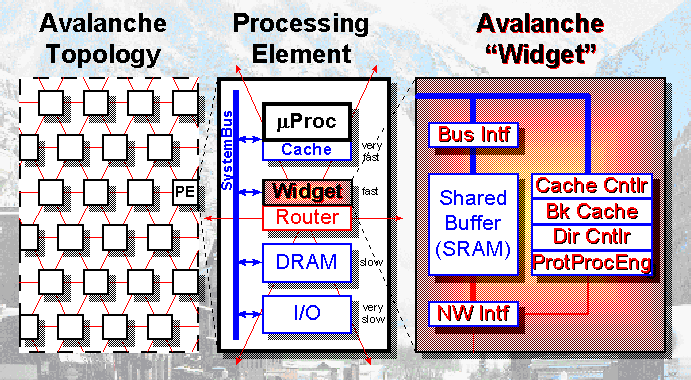
Architecture of Avalanche
在每一個node裡,有一種叫widget的chip,這chip作一些super
computer裡cache controller的功能,還有一些shared
memory controller的message passing,以及一些network的interface。這個project的特色就是用現成的,唯一需要作的就是設計這塊widget。這系統support
message passing和shared memory。在shared
memory方面,一個node要access別的node的memory一定要先經過widget,但是route的工作是和node分開的,route完全在hardware裡作掉了,不會牽涉到CPU,但是loading還是會有一些問題。這project
physically是distributed memory,但programming是shared
memory。在Avalanche,有研究何者應該放在OS裡,何者應該放在hardware裡,這樣可以減少hardware的cost。這個project主要是用到AS-COMA的architecture。
CC-NUMA
non-uniform就是如果在一台電腦裡有四個CPU,都要花同樣的時間去access一塊memory。在這裡因為memory是distributed,access
memory的時間在local和remote會不一樣,所以叫non-uniform。CC-NUMA在super
computer的architecture裡面是說我這CPU
allocate一些data,這些data只有在我自己的memory,別的node沒有這塊data,如果別的node的process想要access上面的data,它就必須經由網路,將得到的data存到自己的cache裡面,那我先介紹一個名詞叫home
node,home node就是我把data拿回來,這data原來所在的node就叫做home
node,home node的memory叫做home
memory。那這個architecture很簡單,就是把data抓回來放在process
cache裡面。但是缺點就是,如果發生了conflict
miss,就會產生很大的overhead,如果它把抓回來的data也存一份到memory,就可以減少overhead。
S-COMA
S-COMA就是為了改進CC-NUMA的缺點,把data也存到memory裡。當它要access
data之前,它先在memory裡面allocate一個page,所以當把data抓進來的時候,不僅拿給process看,而且也backup在memory裡面。但是它的memory使用率不高,導致memory浪費掉,就會發生thrashing,software
overhead還是會非常高。
AS-COMA
這個architecture主要綜合了CC-NUMA(cache
coherent non-uniform memory access)和S-COMA(simple
cache-only memory architecture)。在distributed
shared memory的環境下,conflict miss比在純粹PC環境中的conflict
miss所造成的overhead還大,約有十倍之多。所以這個architecture主要是希望說有辦法能把bottlenet消除掉,所以我們要reduce
remote communication。也就是如果不是經常replace的data,我們就不allocate一塊memory在local端,但是如果經常replace,我們就allocate一塊memory讓它backup。所以這個architecture不僅減少CC-NUMA所造成remote
communication的overhead,也減少了S-COMA所造成software
overhead。
問:你在講shared memory,我以為是一般的架構,就是一個common
memory,然後PE這樣子直接下去access,那你現在等於是把每一個PE本身都有一個memory,感覺上就是distributed
memory。
是distributed memory。
問:所以它physically是distributed
memory,但programming是shared
memory。
對,是shared memory。
問:那你本身memory的addressing是怎麼計算,是算在一起還是個別去address?
當然必須有一個去divide它的physical
address。
問:不是,我是講virtual,從OS的觀點來看。
可是widget只有看到physical,因為它已經到bus了,virtual已經到CPU已經弄掉了,下來以後已經是physical
address。Widget看這零到十是我的memory,十一到二十是另一個node的memory,如果看到十二,那這就不是我的memory,它必須要送到另一個node去作處理,這是完全distributed而且scalable。
問:所以它physically是distributed,它programming是virtual。
問:那你們OS是用什麼?
我們是用BSD 4.4,就像freeBSD一樣。
問:請問一下,你們市場的定位是定位在哪裡?是定位在以前傳統的super
computer,還是……
是scientific computing。
問:那現在像現在好幾家super computer公司倒的倒,那你們的demand是怎麼樣?
可是這樣講你還是需要,因為國家實驗是還是需要,像美國太空總署都是需要,那他們買SGI,一台十六個node,十六個node據我所知要好幾個million以上,我們學校有一個六十四個node,那是2
millions,可是我們有很多 ,SGI的market不一樣,它就是專門對學校,可是這一點就讓很多公司倒掉,所以intel去inter-view,提供我們offer,它現在想先作十六個node,如果市場有需要,以後program又出來,我再加到三十二個node,我是覺得這是正確的方向。如果我要回到國內,因為我們國內有很多intel
box,製作的過程絕對是TOP 1,可是design方面可能就沒有。
問:那這是還可以argue的,那進一步來講,從商業上來講,譬如說PC,反正OS放出來,那全世界很多人都會玩它,可是像這樣一個東西出來的話,hardware
support或software support,你去哪裡找那麼多人support這樣的機器?
可是因為它賣的貴啊,它SGI還是這樣做,自己的OS,自己的hardware。我是不贊成我們是用SGI,可是現在還需要super
computer,因為現在美國測試核彈都是用它。
問:那另外有一個approach叫cluster,那這兩者的比較?
就是有trade-off,像02k有很快的網路,可是問題就是很貴,cluster可以使用現成的workstation,比較買的到的網路來作,可是02k的performance一定是最好的,如果你有一些特別的application,你可以用cluster,可是如果你是用到另一個application,你還是得用SGI的機器。
問:那scientific computing如果沒有寫在哪裡,那要怎麼做?
那就不要作。
問:還是要有,就跟車子一樣,勞斯萊斯這樣貴還是有人買,那大部分的人當然還是會去買裕隆、喜美這些車子,那是看你的approach。
對。
問:我當然最大的考慮是錢嘛,scientific
computing它最重要的就是要錢,那去NSF去申請經費,申請到錢就可以買,如果申請不到錢,其實需要那也是沒有用的。
那他就只好弄比較便宜的,要不然就只好去租super
computer,這個市場倒不大啦,像SGI也快要倒了。
問:我想連老師的point是像hardware這部分,如果intel有這樣的approach,microsoft有沒有這樣子去搭配?因為如果你這樣做,而OS不能搭配的話,所以在你們的lab裡,你們的freeBSD可以自己去customize,適合你們自己的hardware
architecture,可是現在在市場方面,這兩個硬體和軟體的兩大龍頭有沒有辦法從這個方向?
其實他們都有談。像microsoft NT裡面有一塊叫HAL,那個就是讓你customize的地方。它就是讓你hardware和software是分開來的,可是有一些東西還是無法改的,其實你去intel和software公司給你的inter-view,他們給你的feedback不一樣,像intel,我跟他說你最好改一下你的OS,你的performance才會好,它會回答說我沒辦法改,那你到software公司的話,他們會說我們可以改software,hardware不能多作。
問:譬如說我現在有一個program想要平行化,那總有一些地方沒辦法,那如果你把所有能平行化的都平行化,假如它速度變成超快,可是你的scalable還是沒辦法。
真的是depend on application,有的application是非常scalable。
問:那你一定會有scalable的問題,所以你的平行化再怎麼快,還是無法突破極限,那經過那麼多年在parallel的研究,已經有一些經驗。
我覺得這個bottlenet還是沒有辦法突破。可是像現在核子彈,他們都盡量找一些方式讓它能夠平行化,雖然說速度會慢一點,可是當你能平行化以後,我們還有好幾千的node,所以速度還是很快。所以說還是有這個市場,只是說市場很少。我同意這種東西到現在還是沒辦法作到linear
scale。
問:所以一般能平行化的程度是多少?
Linear假設是一好了,0.6到0.7已經是不錯了,因為我們跑到六十四個node,甚至是一百二十八個node,反而還會掉下來,所以目前來講還是會有這個問題。因此在寫軟體時會想辦法去克服,也就是反正會想一個辦法去克服。那今天我主要是講到一個最新的architecture的trend,也就是AS-COMA,因為一種方法實在沒有辦法解決所有的application,所以我們就hybrid。Architecture裡面有一個叫conflict
misses,所謂conflict misses是現在我有data要從memory
load到cache裡面,因為cache很小,而且CPU的chip的area有限,所以conflict
miss很嚴重,因為讀進來的data會蓋過原來的data。那在distributed
shared memory的情形更嚴重,因為在一般的PC裡面,data被蓋過去,如果我還要那個data,我只要到local去抓就好了,因為我只有一台電腦。可是在DSM(distributed
shared memory)裡面,就是因為router的問題、網路的問題,我們有好幾千的node,如果這個data在別的node的memory裡面,當conflict
miss發生時,我必須經過網路到另一個node的memory去抓。當然如果你有兩million甚至三million的錢,你可以買SGI很好的網路,可是當你用cluster,或是一般現成inter-connect來作的話,一般local
access要五十個cycle,remote
access大概是五百個cycle,SGI的好處是remote
access大概只有一百到一百五十個cycle。像我們這個architecture主要是希望說有辦法能把bottleneck消除掉,所以我們要reduce
remote communication。我們有兩個前提,就是用到最少的hardware
support,還有minimize software overhigh。那第二部分的talk,我可能會花比較多的時間在background,那後面就是我們在設計這architecture的detail介紹,最後在真正run一些benchmark,跟別人propose的architecture來比較。OK,第一種architecture叫CC-NUMA(cache
coherent non-uniform memory access),non-uniform就是如果在一台電腦裡有四個CPU,都要花同樣的時間去access一塊memory。在這裡因為memory是distributed,access
memory的時間在local和remote會不一樣,所以叫non-uniform。CC-NUMA在super
computer的architecture裡面是說我這CPU
allocate一些data,這些data只有在我自己的memory,別的node沒有這塊data,如果別的node的process想要access上面的data,它就必須經由網路,將得到的data存到自己的cache裡面,那我先介紹一個名詞叫home
node,home node就是我把data拿回來,這data原來所在的node就叫做home
node,home node的memory叫做home
memory。那這個architecture很簡單,就是把data抓回來放在process
cache裡面。可是有一個問題,我們meomory很大啊,那麼為什麼
如果說這個node conflict miss,如果說這個dead
lock被踢掉了,那當他要access的時候,他還是要用inter-connect去抓回來,又要浪費一些cycle。那為什麼這裡有那麼一大塊的memory它不用,他應該抓還來就把它存在memory裡面,如果說有一些conflict
miss發生後,那他再access的時候,他直接在local
memory一抓就回來了。所以說這個architecture他的問題就在這,他在這塊區域沒用到。
問:那這個hot page你還是要(雜再一起了,聽不清楚)?
所謂hot page就是說,我常常被replace掉,那我應該local就allocate一個page在那邊,那這個就叫做hot
page。
問:你還是要一個page只能存一點點data?
當你access home memory的時候,所有的node回來都是存在這個local
page裡面。假設說我現在有一個home node,我有一個page,那這個node只要access這個page,所有data抓回來都是擺在同一塊local
page裡面,至於address不一樣的問題,controller會有做。Home
memory的一個page對應一個Remote端data的一個page。現在Hybrid
I的一個好處就是說,我要認出這個hot page是哪一個,所以我不是一定要allocate一個page在這邊,我有選擇性,我看到哪一個是hot
page,我就allocate給他就好了,local
memory還是有用到,但是跟S-COMA比較它的software
overhead比較低。
問:那我怎麼確定我跟那Home memory的資料是一致的?因為我只是一個local
copy?
Home memory當別人跟他要資料的時候,假設node
1跟他要資料的時候,它就會說node 1有這個東西,它會maintain在那邊。那當別人要寫進去的時候,同樣一個資料的時候,它也是要跟Home
node問他說,我是不是要這個data?那它因為有maintain這些資訊,所以他知道說node1已經有一個share
copy了,那就必須要send一個message跟node
1說,有人要寫進去了,你把你的data invalidate掉,就是把它flush掉。所以DSA
Controller很重要,它要maintain一些information,哪一些node已經有我這個copy,哪一些沒有。
問:invalidation的速度有多快?
要看你的網路,如果普通的話可能要500 cycles,SGI可能要50個cycles。
因為第一個architecture CC-NUMA沒有牽涉到memory,只有牽涉到cache,就是說即使memory
pressure增加,execution tome還是都是一。因為Simple-COMA在memory
pressure如果是很低的話,那即使說我有cache被replace掉,我直接從你local
memory就可以抓到,若有很多memory的話,它比CC-NUMA要好。可是當你memory
pressure變高的話,execution time會像火箭一樣衝上來。在Reality
Hybrid Model裡面,他剛開始的時候會比Simple-COMA差一點,可是當memory
pressure go high的時候,它會比S-COMA好;可是當memory
pressure到90%的時候,它會跟S-COMA一樣開始往上。哪因為我們這個architecture
support兩種:CC-NUMA,S-COMA,我們要試著去找說Optimal的performance,當在memory
pressure是low的時候,我想跟Simple-COMA在一起,當memory
pressure是high的時候,至少我要maintain我的performance跟CC-NUMA一樣,因為我兩種都support。
那第二部分首先我比較AS-COMA跟其他Model有什麼不一樣。其他的model就如你剛才所見,剛開始不錯,比Simple-COMA好,可是後來就衝上來了。那AS-COMA剛開始跟Simple-COMA一樣,然後當memory
pressure go high 的時候,就跟CC-NUMA一樣。
Objective
The objective is the design and implementation of a communications interface
for commodity workstations that intelligently integrates message
passing into the memory-hierarchy and supports distributed
shared memory in a manner that is fast, flexible, and adaptive. The
goal is to provide these capabilities to production workstations without
requiring replacement of any existing subsystems and without compromising
workstation performance in any way. The result will be construction of
a 64 node multicomputer prototype using HP
Runway based workstations, the Myrinet
communications fabric, and our custom interface board to demonstrate extremely
low latency user-to-user message passing and highly effective distributed
shared memory.
Approach
Avalanche is a communications architecture that recognizes the importance
of memory hierarchies in the real end-to-end cost of interprocessor communications.
It provides both message passing (MP) and distributed shared memory (DSM)
because each approach has certain advantages over the other and both together
promise to address a wide range of applications better than either in isolation.
Integrating MP and DSM in the same interface exploits resources required
by the common needs to interact closely with the memory hierarchy and coherence
bus of the host node. DSM relies on this closeness for maintaining consistency
of shared data, while MP needs to address the growing contribution of memory
hierarchy costs to end-to-end communications costs. The Avalanche MP approach
utilizes a combination of simple, but powerful, message delivery capabilities
and a set of safe lightweight protocols to deliver data directly into a
receiver's virtual address space at the proper level in the physical memory
hierarchy. The Avalanche DSM approach combines a number of consistency
protocols with two adaptively selected shared memory models (Simple-COMA
and CC-NUMA) to enable the system to match DSM support to application requirements.
It is pipelined, highly parallel hardware DSM support will provide efficient
shared memory operations while minimizing the occupancy-based latency that
processor-based approaches are susceptible to.
While close integration to the memory hierarchy is important to success
for Avalanche, cost and real performance are equally important. Approaches
that significantly diminish the normal performance of the constituent workstations
are unacceptable. A decrease in single system performance increases the
level of multicomputing efficiency that the approach must deliver. Moreover,
it raises doubts about the applicability of the approach to future systems
where basic workstation performance will undoubtedly be higher. The Avalanche
approach is to design an interface that can be plugged into the system
bus. It does not rely on replacing (and reinventing) either the cache that
is close to the processor or the memory controller. Both subsystems are
too tightly tuned to a particular architecture and are therefore too costly
to replace without a significant effect on system balance.
(ICPP98 -- Aug 1998)
Abstract
Scalable shared memory multiprocessors traditionally use either a cache
coherent non-uniform memory access (CC-NUMA) or simple cache-only memory
architecture (S-COMA) memory architecture. Recently, hybrid architectures
that combine aspects of both CC-NUMA and S-COMA have emerged. In this paper,
we present two improvements over other hybrid architectures. The first
improvement is a page allocation algorithm that prefers S-COMA pages at
low memory pressures. Once the local free page pool is drained, additional
pages are mapped in CC-NUMA mode until they suffer sufficient remote misses
to warrant upgrading to S-COMA mode. The second improvement is a page replacement
algorithm that dynamically backs off the rate of page remappings from CC-NUMA
to S-COMA mode at high memory pressure. This design dramatically reduces
the amount of kernel overhead and the number of induced cold misses caused
by needless thrashing of the page cache. The resulting hybrid architecture
is called adaptive S-COMA (AS-COMA). AS-COMA exploits the best of S-COMA
and CC-NUMA, performing like an S-COMA machine at low memory pressure and
like a CC-NUMA machine at high memory pressure. AS-COMA outperforms CC-NUMA
under almost all conditions, and outperforms other hybrid architectures
by up to 17% at low memory pressure and up to 90% at high memory pressure.
(April 1997)
Abstract
This paper describes experience in parallelizing an execution-driven architectural
simulation system used in the development and evaluation of the Avalanche
distributed architecture. It reports on a specific application of conservative
distributed simulation on a shared memory platform. Various communication-intensive
synchronization algorithms are described and evaluated. Performance results
on a bus-based shared memory platform are reported, and extension and scalability
of the implementation to larger distributed shared memory configurations
are discussed. Also addressed are specific characteristics of architectural
simulations that contribute to decisions relating to the conservatism of
the approach and to the achievable performance.
(December 1996)
Abstract
The key to crafting an effective scalable parallel computing system lies
in minimizing the delays imposed by the system. Of particular importance
are communications delays, since parallel algorithms must communicate frequently.
The communication delay is a system-imposed latency. The existence
of relatively inexpensive high performance workstations and emerging high
performance interconnect options provide compelling economic motivation
to investigate NOW/COW (network/cluster of workstation) architectures.
However, these commercial components have been designed for generality.
Cluster nodes are connected by longer physical wire paths than found in
special-purpose supercomputer systems. Both effects tend to impose intractable
latencies on communication. Even larger system-imposed delays result from
the overhead of sending and receiving messages. This overhead can come
in several forms, including CPU occupancy by protocol and device code as
well as interference with CPU access to various levels of the memory hierarchy.
Access contention becomes even more onerous when the nodes in the system
are themselves symmetric multiprocessors. Additional delays are incurred
if the communication mechanism requires processes to run concurrently in
order to communicate with acceptable efficiency. This paper presents the
approach taken by the Utah Avalanche project which spans user level code,
operating system support, and network interface hardware. The result minimizes
the constraining effects of latency, overhead, and loosely coupled scheduling
that are common characteristics in NOW-based architectures.
Support for Distributed Shared Memory in Avalanche
(ASPLOS'96 Workshop -- October 1996)
(Ghostview incompatible, yet printable postscript slides available here.)
Abstract
This talk concentrated on the unique design features present in Avalanche
for supporting scalable shared memory, including support for both the Simple
COMA and CC-NUMA architectures, support for multiple coherency protocols,
and some low-level design optimizations. The talk also discusses a number
of challenges that we faced in using off-the-shelf hardware over which
we had little to no control. Detailed implementation issues and example
operations are included to illustrate the DSM architecture, and preliminary
simulation-derived results are presented.
(June 1996)
Abstract
Version 2.0 of the Myrinet simulation package was designed to allow a high
degree of configurability of the modeled network. Version 1.0 modeled only
simple square mesh topologies with 4-port switches, and users could specify
only a limited number of switch parameters. As Myricom released larger
and faster versions of their Myrinet switches, the V1.0 simulation model
became obsolete. Users of the V2.0 package can specify arbitrary network
topologies composed of Myrinet switches with different number of ports.
For example, 4-port and 32-port switches can be used in a single system.
Because the V2.0 model supports arbitrary topologies, simple X-then-Y source
routing is no longer sufficient to model the required routing. Thus, users
of the V2.0 package must specify the routing table themselves. In addition,
to track improvements to the circuit technologies used in the Myrinet switches,
the clock rate, latency and bandwidth have been parameterized. Users can
change the parameters in order to meet their simulation needs.
Myrinet Simulation Package
Source Code (235 KB)
(March 1996)
Abstract
This document describes Paint, an instruction set simulator based
on Mint.
Paint interprets the PA-RISC instruction set, and has been extended to
support the Avalanche Scalable Computing Project. These extensions include
a new process model that allows multiple programs to be run on each processor
and the ability to model both kernel and user code on each processor. In
addition, a new address space model more accurately detects when a program
is accessing an illegal virtual address, allows a program's virtual address
space to grow dynamically, and does lazy allocation of physical pages as
programs need them.
Note that this document is intended to be an addendum to the original
Mint technical report, which the reader should consult for an overview
of the Mint simulation environment and terminology. This preliminary version
of the document is intended for people who plan to use Paint as a simulation
engine, not modify it.
Click here to request the
latest version of the PA-Int software package (~8 MB).
(March 1996)
Abstract
In this paper, we present a new partial order reduction algorithm that
can help reduce both space and time requirements of automatic verifiers.
The partial order reduction algorithms described in [God95, Hol94] (both
incorporated in SPIN [Hol91]) were observed to yield very little savings
in many practical cases due to the proviso in them. Our algorithm, called
the two-phase algorithm, is different from these algorithms in that
it avoids the proviso, and follows a new execution strategy consisting
of alternating phases of depth-first-search and partial order reduction.
The two-phase algorithm is shown to preserve safety properties. It has
been implemented in a new verifier which, like SPIN, takes Promela as input.
Comparisons between these algorithms and the two-phase algorithm are provided
for a significant number of examples, including directory based protocols
of a new multiprocessor where significant performance gains are obtained.
(March 1996)
Abstract
Minimizing communication latency in message passing multiprocessing systems
is critical. An emerging problem in these systems is the latency contribution
costs caused by the need to percolate the message through the memory hierarchy
(at both sending and receiving nodes) and the additional cost of managing
consistency within the hierarchy. This paper, considers three important
aspects of these costs: cache coherence, message copying, and cache miss
rates. The paper then shows via a simulation study how a design called
the Widget can be used with existing commercial workstation technology
to significantly reduce these costs to support efficient message passing
in the Avalanche multiprocessing system.
(January 1996)
Abstract
The use of workstations on a local area network to form scalable multicomputers
has become quite common. A serious performance bottleneck in such ``carpet
clusters'' is the communication protocol that is used to send data between
nodes. We report on the design and implementation of a class of communication
protocols, known as sender-based, in which the sender specifies the locations
at which messages are placed in the receiver's address space. The protocols
are shown to deliver near-link latency and near-link bandwidth using Medusa
FDDI controllers, within the BSD 4.3 and HP-UX 9.01 operating systems.
The protocols are also shown to be flexible and powerful enough to support
common distributed programming models, including but not limited to RPC,
while maintaining expected standards of system and application security
and integrity.
(November 1995)
Abstract
Efficient synchronization is an essential component of parallel computing.
The designers of traditional multiprocessors have included hardware support
only for simple operations such as compare-and-swap and load-linked/store-conditional,
while high level synchronization primitives such as locks, barriers, and
condition variables have been implemented in software. With the advent
of directory-based distributed shared memory (DSM) multiprocessors with
significant flexibility in their cache controllers, it is worthwhile considering
whether this flexibility should be used to support higher level synchronization
primitives in hardware. In particular, as part of maintaining data consistency,
these architectures maintain lists of processors with a copy of a given
cache line, which is most of the hardware needed to implement distributed
locks.
We studied two software and four hardware implementations of locks and
found that hardware implementation can reduce lock acquire and release
times by 25-94% compared to well tuned software locks. In terms of macrobenchmark
performance, hardware locks reduce application running times by up to 75%
on a synthetic benchmark with heavy lock contention and by 3%-6% on a suite
of SPLASH-2 benchmarks. In addition, emerging cache coherence protocols
promise to increase the time spent synchronizing relative to the time spent
accessing shared data, and our study shows that hardware locks can reduce
SPLASH-2 execution times by up to 10-13% if the time spent accessing shared
data is small.
Although the overall performance impact of hardware lock mechanisms
varies tremendously depending on the application, the added hardware complexity
on a flexible architecture like FLASH or Avalanche is negligible, and thus
hardware support for high level synchronization operations should be provided.
(August 1995)
Abstract
This document describes the interface and functional specification of a
Protocol Processing Engine (PPE) for workstation clusters. The PPE is intended
to provide the support necessary to implement low latency protocols requiring
only low resource (cpu and bus bandwidth) consumption.
(February 1995)
Abstract
We investigate techniques for reducing the memory requirements of a model
checking tool employing explicit enumeration. Two techniques are studied
in depth: (1) exploiting symmetries in the model, and (2) exploiting sequential
regions in the model. The first technique resulted in a significant reduction
in memory requirements at the expense of an increase in run time. It is
capable of finding progress violations at much lower stack depths. In addition,
it is more general than two previously published methods to exploit symmetries,
namely scalar sets and network invariants. The second technique comes with
no time overheads and can effect significant memory usage reductions directly
related to the amount of sequentiality in the model. Both techniques have
been implemented as part of the SPIN verifier.
(January 1995)
Abstract
This note describes the Direct Deposit Protocol (DDP), a simple protocol
for multicomputing on a carpet cluster. This protocol is an example of
a user-level protocol to be layered on top of the low-level, sender-based
protocols for the Protocol Processing Engine. The protocol will be described
in terms of its system call interface and an operational decription.
(January 1995)
Abstract
We present design details and some initial performance results of a novel
scalable shared memory multiprocessor architecture. This architecture features
the automatic data migration and replication capabilities of cache-only
memory architecture (COMA) machines, without the accompanying hardware
complexity. A software layer manages cache space allocation at a page-granularity
- similarly to distributed virtual shared memory (DVSM) systems,
leaving simpler hardware to maintain shared memory coherence at a cache
line granularity.
By reducing the hardware complexity, the machine cost and development
time are reduced. We call the resulting hybrid hardware and software multiprocessor
architecture Simple COMA. Preliminary results indicate that the
performance of Simple COMA is comparable to that of more complex contemporary
all-hardware designs.
(March 1994)
Abstract
Formal verification of hardware and software systems has long been recognized
as an essential step in the development process of a system. It is of importance
especially in concurrent systems that are more difficult to debug than
sequential systems. Tools that are powerful enough to verify real-life
systems have become available recently.Model checking tools have become
quite popular because of their ability to carry out proofs with minimal
human intervention. In this paper we report our experience with SMV, a
symbolic model verifier on practical problems of significant sizes. We
present verification of a software system, a distributed shared memory
protocol, and a hardware system, the crossbar arbiter. We discuss modeling
of these systems in SMV and their verification using temporal logic CTL
queries. We also describe the problems encountered in tackling these examples
and suggest possible solutions.
Abstract
For a parallel architecture to scale effectively, communication latency
between processors must be avoided. We have found that the source of a
large number of avoidable cache misses is the use of hardwired write-invalidate
coherency protocols, which often exhibit high cache miss rates due to excessive
invalidations and subsequent reloading of shared data. In the Avalanche
project at the University of Utah, we are building a 64-node multiprocessor
designed to reduce the end-to-end communication latency of both shared
memory and message passing programs. As part of our design efforts, we
are evaluating the potential performance benefits and implementation complexity
of providing hardware support for multiple coherency protocols.
Using a detailed architecture simulation of Avalanche, we have found that
support for multiple consistency protocols can reduce the time parallel
applications spend stalled on memory operations by up to 66% and overall
execution time by up to 31%. Most of this reduction in memory stall time
is due to a novel release-consistent multiple-writer write-update protocol
implemented using a write state buffer.
Abstract
This note describes a prototype DSM protocol and directory cache controller
design for the architectural simulation of a carpet cluster of nodes with
modified PA7100 CPUs and two levels of cache. The design is functionally
decomposed into three separate blocks: the Context Sensitive Cache Controller
Unit, the Directory Controller, and the Network Controller. Four access
protocols are supported by the design: local, migratory, write invalidate,
and write shared.
This no longer represents the current architecture,
but is an early overview of the project goals.
Abstract
As the gap between processor and memory speeds widens, system designers
will inevitably incorporate increasingly deep memory hierarchies to maintain
the balance between processor and memory system performance. At the same
time, most communication subsystems are permitted access only to main memory
and not a processor's top level cache. As memory latencies increase, this
lack of integration between the memory and communication systems will seriously
impede interprocessor communication performance and limit effective scalability.
In the Avalanche project we are redesigning the memory architecture of
a commercial RISC multiprocessor, the HP PA-RISC 7100, to include a new
multi-level context sensitive cache that is tightly coupled to the communication
fabric. The primary goal of Avalanche's integrated cache and communication
controller is attacking end to end communication latency in all of
its forms. This includes cache misses induced by excessive invalidations
and reloading of shared data by write-invalidate coherence protocols and
cache misses induced by depositing incoming message data in main memory
and faulting it into the cache. An execution-driven simulation study of
Avalanche's architecture indicates that it can reduce cache stalls by 5-60%
and overall execution times by 10-28%.
Abstract
The next generation of scalable parallel systems (e.g., machines by KSR,
Convex, and others) will have shared memory supported in hardware, unlike
most current generation machines (e.g., offerings by Intel, nCube, and
Thinking Machines). However, current shared memory architectures are constrained
by the fact that their cache controllers are hardwired and inflexible,
which limits the range of programs that can achieve scalable performance.
This observation has led a number of researchers to propose building programmable
multiprocessor cache controllers that can implement a variety of caching
protocols, support multiple communication paradigms, or accept guidance
from software. To evaluate the potential performance benefits of these
designs, we have simulated five SPLASH benchmark programs on a virtual
multiprocessor that supports five directory-based caching protocols. When
we compared the off-line optimal performance of this design, wherein each
cache line was maintained using the protocol that required the least communication,
with the performance achieved when using a single protocol for all lines,
we found that use of the ``optimal'' protocol reduced consistency traffic
by 10-80%, with a mean improvement of 25-35%. Cache miss rates also dropped
by up to 25%. Thus, the combination of programmable (or tunable) hardware
and software able to exploit this added flexibility, e.g., via user pragmas
or compiler analysis, could dramatically improve the performance of future
shared memory multiprocessors.
http://dslab.csie.ncu.edu.tw/
台灣科技大學電子工程技術系平行處理暨分散式系統實驗室
http://dcs2.et.ntust.edu.tw/
平行處理與計算理論實驗室
http://axp2.csie.ncu.edu.tw/
http://www.ibm.com.tw
泰維電腦科技股份有限公司
http://www.topware.com.tw/
http://java.csie.nctu.edu.tw/
http://csrc.act.nctu.edu.tw/csrcweb/yeareport/3/
http://www.partment.com.tw/Phoenics/index.html
國科會
http://db2serv.cc.nctu.edu.tw/cgi-bin/top20.cgi?915
http://red-herring.cs.uiuc.edu/papers/stackhtml/sc95.html
http://aswww.phy.ncu.edu.tw/ppcs/wwwsite.htm
http://www.myri.com/
Myricom Home Page