| Some Simple Shell Script Examples |
|---|
|
|
這裡的 shell script 分為兩種,一種是直接在 command line 下的,
所有參數都是直接給定的,
另一種則是存成檔案做成可以重複使用的指令,
所需的參數在script 中用變數代表(例如 $1, $2, $*等變數),
由使用者在叫用該 script 時才給定的。
在「用法」 裡有說明Script的叫用方式,但有些 script 沒有標明「用法」,
讀者可以從 script 中輕易的看出如何使用,自行製作成指令。
|
| 功能 | grep pattern from several files, output with line numbers
| 用法 | gn [options] <pattern> <filename1> <filename2> ...
| | grep -n $*
| 解釋
|
可以用來檢視哪些檔案含有某一字串,
這個 script 很單純的將使用者所下的grep 指令加上 -n 選項而已。
讀者如果會常常用到時,建議製作成指令以便重複使用,省點打鍵盤的功夫。
| |
|---|
| 功能 | check the tail lines of your mail box
| | tail -100 /usr/spool/mail/uname
| 解釋
|
假設系統將各人的信箱放在 /usr/spool/mail/yourname
| 這個指令將信箱中的最後100行印出來, 可用來檢查是否有新信件進來。 註
| 新信件如有附加檔或encoded text,不容易檢視內容。
| |
|---|
| 功能 | double space a text file
| | sed G <filename>
| 解釋
| G 是 sed 的指令,將 buffer 的內容加在每一行後面
| 因為buffer內的初始值是空的,其效果等於 在每一行文字後面加上一個空行。 請注意,G 是 sed 內的一個一般性指令,並非特意為double space的功能 所設計的。 |
|---|
| 功能 | count the number of lines for a file, number
only
| |
wc -l $1 | cut -c1-8
| 解釋
|
wc 這個指令會列出一個檔案的行數、字數、及字元數,其格式
隨系統而不同,使用者必須依據實際情況調整。
在很多script中都會用到檔案的行數作為參數,所以有必要
設計一個指令將所需要的資訊從wc 這個指令所輸出的一堆資訊中提出來。
| |
|---|
| 功能 | 產生從1開始的數目序列
| 用法 | count <number>
| Script m5a
|
|
Script m5b
|
如果你的系統有支援 $(( ... )) 這種運算的話,這個script
可以寫得簡單一些。
|
|
|  解釋 m6 |
|
使用者可以自己找一個或製作一個長檔案作為 longfile。 | head -$1 <longfile> | awk "{print NR}"
| | head -$1 <longfile> | perl -p 'print $.'
| 註
| 上面這些另類檔案之成功與否,依賴著 longfile 的大小,
是個漏洞,因此並非是嚴謹的程式,不能拿來作為正式的應用程式使用,
本文舉這個例子,只是用來展示「另類」的運算邏輯之用。
| |
|---|
| 功能 | 產生一個區間的數目序列
| 用法 | numberseq <begin-number> <end-number>
| Script m5b
|
|
|
|---|
| 功能 | 產生一個區間的等加序列
| 用法 | numberseq <begin-number> <end-number> <skip-number>
| Script m5c
|
|
Script m5d
|
|
|
|---|
| 功能 | Instant Message
| | echo "Hello!" > /dev/ttyxx
| | cat filename > /dev/ttyxx
| 解釋 m9,m10
| Script m9 將"Hello!"字串送到終端機 ttyxx 上,
而 Script m10 將檔案 <filename> 的內容送到終端機 ttyxx 上,
這就是一種instant message。
| 終端機在Unix 裡被視為一個檔案,其權限通常是對所有使用者開放的, (當然使用者可以關閉權限), 任何使用者可以將任何資訊送進這些檔案,其效果等於將資訊展現 在那個終端機上。使用者可以利用 who 這個指令,找出收訊者的終端機 編號。(uid 後面即是 terminal id, 將前面加上 /dev/ 即可得到對應的檔名)。 | cat < /dev/ttyxx
| 解釋 m11
|
既然別人的終端機可以寫入,那當然也可以讀,這個指令
可以讓人偷窺他人在終端機上所敲的任何鍵!!
不過,別慌,系統的初始設定應該會將他人讀這個檔案的權限關閉,
只有 super user 可以讀得到這個檔案。
| |
|---|
| 功能 | search a file recursively
| | find $HOME -name <pattern> -print
| | find . -name <pattern> -print
| 解釋
|
Script m12 從 $HOME 開始往下搜尋名為 <pattern> 的檔案,
| Script m13 從現在的工作目錄開始往下搜尋名為 <pattern> 的檔案。 <pattern>裡可以含有萬用字元,但必須包含在""之內,以免被 shell 在執行之前即被展開。 |
|---|
| 功能 | 如何讓程式在logout以後還能繼續執行
| | nohup command [ arguments ] &
| |
|---|
| 功能 | How to make a "script" to judge which "shell" we are in?
| | echo $SHELL
| |
|---|
| 功能 | finding files that are less than a day old
| | find / -amin +120 ...
| | find . -newer <filename> -print
| | find . -mmin +120 -type f -exec rm -r {} \;
| |
|---|
| 功能 | 分割檔案 split
| |
split <filename>
| 解釋
| 將一個檔案分成數個 1000 行的檔案
| |
split -b 1m <filename>
| 解釋
| 將一個檔案分成數個 1mb 的檔案
| |
|---|
| 功能 | delete empty file
| |
find / -size 0 \(-name \*.dat -o -name sh\*.dat \) -exec rm -f {} \;
| |
|---|
| 為一堆檔案更改檔名 |
|---|
| 功能 | change file names for a group of files
| |
|
解釋
| 這個 script 將以檔名為 Image 開頭的 JPG 影像檔全部更改檔名,在
原檔名之前加上"nccu"字串。
當然,如果嫌檔名太長的話,可以加幾個指令,可以做得更好。
| 如果要將數位相機照得的一堆影像檔改個較有意義的檔名時, 這非常好用。 |
|---|
| 功能 | change file names for a group of files
| |
|
解釋 | 這個 script 比較general, 它是產生如下的編輯指令
|
| ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
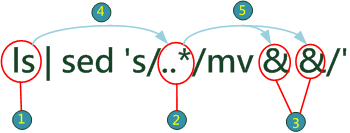
| 功能 | 將 *.txt 改成 *.csv
| |
|
|
|
|
|
| |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|



| 功能 | 將 nccu.* 改成 NCCU.*
| |
|
|
|
|
|
| ||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
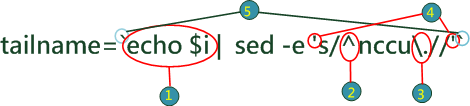


| 功能 | rename all files in the currect directory to the lower case
| |
|
解釋 |
| 
|
|---|
| Filtering and Conversion |
|---|
| 功能 | convert text file in DOS format into UNIX format
| Script c1
|
|
解釋
|
在script 中,^M 是一個控制字元,請
不要誤解成 '^' 及 'M' 兩個字元。
| 此外,shell 將"<<%" 與 "%" 兩個符號之間的 text 送給 ex 作為使用者之 鍵盤輸入,由於 $ 這個字元在 shell 中是特殊字元,必須 加上escape字元,其原始 editing script 如下:
|
|---|
| 功能 | filtering out words: is, this, a
| |
sed "s/this//;s/is//;s/a//;s/ *//g"
| 解釋
|
| Input: this is a dumb question Desired Output: dumb question if you want to filter 'is' but not "isn't", that wouldn't work; you could still use sed, but I think I'd use perl so that I don't have to code 3 sed substitutions for every word: |
sed "s/this//;s/is//;s/a//;s/ *//g"
| |
perl -p -e 's/(^|\s+)is(\s+|$)//g;s/(^|\s+)this(\s+|$)//g;'
| |
perl -p -e 's/(^|\s+)(is|this)(\s+|$)//g;'
| |
|---|
| 功能 | converting string
| ||
|---|---|---|---|
| |
| ||
| |
perl -p -e 's/(\d\d[A-Z][A-Z][A-Z][A-Z])/\n$1/g'
| 解釋
|
It reads "insert newline before every occurrence
of two numbers followed by four uppercase letters."
| If spaces/tabs on a line count as a blank line, then you need a more complicated expression. |
| 功能 | swap the first two columns
| |
%s/^\([^ ]*\) \([^ ]*\)/\2 \1/
| 解釋
| 注意 \( \) \1 \2 在 ex/sed 裡的意義
| | awk '{print $2 $1}'
| 解釋
| 注意 ' ' 這對引號在這裡的用處,它可以避免shell 將$1, $2
當成變數。讀者應盡可能熟悉 ' ', " ", 及 ` ` 這幾對引號的用法。
| |
|---|
| 功能 | convert a file into 2 column
| | pr -t -l66 -w80 -2 <filename>
| 註
|
現在有 Winword 作為文件的編輯程式,在Unix將文件做
兩欄式的編排之需求已經大不如前。
| |
|---|
| 功能 | interlave a single column file into 2 column
| |
| 註
|
| |
|---|
| Cut a block of lines from a file |
|---|
| 功能 | 檔案片段之截取 (cut a block of lines)
| 用法 | gl <beginline> <endline> <filename>
| | sed -n -e "$1,$2p" $3
| Script b2
|
|
解釋 b1,b2
| 使用 Script b1,b2 ,使用者要提供開始及結束之行數
Script b2 比 Script b1 快,當awk 將輸入檔案讀入時,讀到 <endline>
時就停止,而Script b1 則會一直讀到最後一行,當檔案很大時會浪費很多時間。
| | awk '/<beginline>/,/<endline>/' <filename>
| 解釋 b3
| 使用這個指令時使用者不是輸入行數,而是
輸入含有 <beginline> 字串的行及
含有 <endline> 字串的行。
| Script b4
| |
解釋 b4
|
同上,但輸出時不包括 <beginline>以及<endline>這兩行。
| 輸入資料每一行只有一個 number時 Script b4
| |
解釋 b5
|
同上,但比對輸入資料第二欄位內含的數字
| |
|---|
| 功能 | delete a block of lines from a file
| 用法 | dl <beginline> endline> <filename>
| |
解釋
|
這個script 先製作一個編輯指令檔,再利用它來編輯原文,
備份留在 tmp.o
| |
|---|
| 功能 | Delete all lines that contain some string
and output to STDOUT
| | grep -v "string" <filename>
| |
|---|
| 功能 | delete blank lines from a file and output to STDOUT
| | egrep -v '(^$)' <filename>
| 解釋
| 注意 -v 在 egrep 裡的作用,而 '^$' 在
regular expression 中代表空行
| |
|---|
| 功能 | replace a block of lines of a file
| 用法 | rl <beginline> <endline> <filename> <filename>
| |
|
|---|
| GrepDom - Basic |
|---|
|
我們常常需要處理多欄文字檔,例如大量的實驗數據,而
常常需要根據某欄位的值作為條件抽出該列,甚至該列的某些欄值。
就像關聯式的資料庫裡的 Selection 加 Projection 的動作。
可惜 grep 並不能指定比對的欄位,只能利用 awk 這類工具來處理。
例如:
|
|
|
|
而下面這個 script 則先產生一個 awk script ,
再用這個 awk script 來處理輸入資料,結果相同。
|
echo '$2 == 30 {print $4, $1}' > awk.script
awk -f awk.script inputfile
|
|---|
| GrepDom - 可任意指定比對的欄位 |
|---|
|
如果使用者希望能彈性的指定比對的欄位以及印出的欄位,
就需要比較高明的 script
Take the first argument as the column position, the
second as the given pattern, and the third
as input file to filter out those lines
whose value at the given column matches to the
given pattern.
|
|
|
|
|
為增加實用性,可增加指定 field delimiter 的 option
|
| GrepDom - 可任意指定比對的欄位及輸出欄位 |
|---|
|
Same as previous version, but with the 4th and
after arguments as the columns to be printed
It can be viewed as a Selction after a Projection operations in Relational database.
|
|
|
|
Script 1 (使用迴圈打造 Ex Script,再用 Ex script 編輯 Awk Script)
|
|
|
|---|
|
Script 2 (使用迴圈打造一個變數,再展開此變數加進 Awk Script)
|
|
| ||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
 |
|
|
Script 3 (不用迴圈)
|
|
|
|---|
|
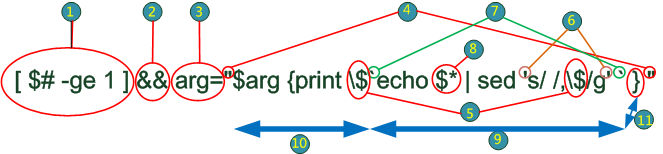
第四行之解釋 (以 grepdom 2 30 input 4 2 3 為例)
|
 |
|---|
| 1 | 檢查是否有指定輸出欄位 | 7 | 抓出 echo $* | sed 's/ /,$/g' 的結果
| 2
| 若有指定輸出欄位,則執行 3
| 8
| 全部的輸入變數,以空白隔開,得到 4 2 3
| 3
| 將後面的字串放進 arg
| 9
| 以 sed 將 $* 中的空白全部改成 ,$,得到 4,$2,$3
| 4
| 利用 " " 將字串包起來
| 10
| 字串 $2 ~ /30/ {print $
| 5
| 保留 $ 字元,避免被當成變數
| 11
| 字串 }
| 6
| 利用 ' ' 將送給 sed 的指令包起來 | 's/ /,$/g' 9-11
| $2 ~ /30/ {print $4,$2,$3}
| |
|---|
|
Script 4 (不用迴圈)
|
|
|
|---|
|
Script 5 (最簡版)
|
1 arg="\$$1~/$2/"
2 shift 2 #捨棄前面二個參數,剩下輸出欄位參數
3 [ $# -ge 1 ] && arg="$arg {print \$`echo $* | sed 's/ /,\$/g'`}"
4 cat | awk "$arg"
|
|---|
| FTP |
|---|
| 功能 | batch ftp a file
| |
|
|
|---|
| 功能 | batch ftp many files
| |
|
|
|---|
| Math: Compute Average, Maximum and Minimum |
|---|
| 功能 | compute average of a column
| 用法 |
avg <column> <filename>
| |
|
|
|---|
| 功能 | compute the maximum of any column
| 用法 | max <column> <filename>
| |
|
|
|---|
| Spelling Tools |
|---|
| 功能 | find an English word
| 用法 (例) | wordhelp con v en t
| ( e.g. looking for the word "convenient") |
|
解釋
|
很多Unix 系統都有個spell的指令,這個指令一定會用到
一個字典,其中含有大部分的英文單字,我們可以運用
這個檔案來做很多跟字典有關的工作。
使用者可以嘗試找找這個檔案 /usr/lib/dict/all。
| wordhelp 這個script 是筆者最常用的script,寫英文文章時幫助非常大。 我們對一個英文字的拼法不熟時,查一般的字典也無從下手, 可能要試很多次,將一部字典翻來覆去才能找到要查的字。 wordhelp 這個 script 可讓使用者輸入一個英文字的某些片段,就可以將含有 這些片段的英文字列出來,而同時含有這些片段的英文單字 屈指可數,很容易就可挑出自己想找的單字。 請注意,這個Script 出現了一個罕見的 shift 指令,這是 shell 裡一個重要的指令,可以將使用者在command line 下的參數做個變動, 將 $1 捨棄,而將後面的 $2, $3, $4 等往前移動,如此,在script 中就可以將原代表所有參數的變數符號"$*"用來代表 $2, $3, $4 等參數。 |
|---|
|
Homework: 設計一個可以幫助 word puzzle (填字遊戲) 的指令?
|
| 功能 | grep with multiple patterns
| 用法 | mgrep <pat1> <pat2> <pat3> ...
| |
|
Alternative by fgrep
解釋
|
Script s2 會將STDIN含有數個指定字串的「行」抓出來,
使用者可輕易更改這個script,讓他可以grep 更多的pattern。
對於常常使用的人,可省下許多時間。下面的 spellcorrect 會用到
這個關鍵的 script。
| |
|---|
| 功能 | Spelling Corrector
| 用法 | spellcorrect <filename>
| |
|
解釋
|
| 在Unix 上寫英文文章時,這個script 可以幫忙更改錯字, 省下很多麻煩的編輯動作,非常有用。  問題 | 利用這個script時,有時候要注意編輯指令檔的正確性,
萬一發生錯誤時,可能會破壞原檔案,改到不該改的字。
例如,如果文章裡有個 "th"的字被挑出來,使用者如果
將這個指令
1,$s/th/th/g
改成
1,$s/th/the/g
的話,後果將會很嚴重。
| 此外,ex 是一個 atomic 的程式, (do all or do nothing), 如果其中有一個編輯指令失敗,最後的 w 將不會作用,導致 執行失敗。 例如,下面的編輯指令會失敗。
|
|---|
| Scripts for HTML |
|---|
| 功能 | generate a color table
| |
|
解釋
|
本 script 會產生一段 HTML 碼,這段 HTML 碼在瀏覽器上會
顯示一個色表,裡面有各種顏色及其對應的 RGB 碼,
使用者可輕易改寫,增加更多的顏色。
| 結果
|
|
註
|
這個 Script 裡 R,G,B 的參數如果改為 00, 33, 66, 99, CC, FF,就可以
產生一個展示216安全網頁顏色的 HTML 檔
| |
|---|
| Code Generator 1 |
|---|
|
Page Show
|
|
產生 Hyper links to 24 種不同的換頁效果網頁
|
<head> <title>網頁切換效果</title> <meta http-equiv="Page-Enter" content=" revealTrans(Duration=3.0,Transition=0) "> </head> <body background="image.jpg"> </body> |
|---|
1.產生 0-23 一組數字 > count (Can be done manually too)
| 2. 利用 count 產生一個 script, copy 24 個jpg file 並 rename to
image0.jpg, image1.jpg,... image23.jpg
| 3. 製造一個 含有上述 code 的 template 檔
| 4. 利用 count 及 template 產生 24 個不同換頁效果的檔案
| 5. 利用 count 產生一個HTML 檔,含有24 個Hyperlink 連到24個產生的檔案。
| |
|---|
|
Script for Step 4 and 5
|
echo "<HTML><TABLE border=1>" for i in 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 do f=pageshow$i.htm sed -e "s/=0/=$i/" -e "s/image/&$i"/ template.htm > $f echo "<TR><TH><A href=$f><font size=3>$i</A>" done echo "</TABLE></HTML>" |
|---|
| Code Generator 2 |
|---|
|
To generate strings.xml for Eclipse/Android
|
|
Input string definition
|
stringvar1 This is String Variable 1 stringvar2 This is String Variable 2 stringvar3 This is String Variable 3 stringvar4 This is String Variable 4 stringvar5 This is String Variable 5 stringvar6 This is String Variable 6 |
|---|
|
Output to strings.xml
|
<?xml version="1.0" encoding="utf-8"?> <resources> <string name="stringvar1">This is String Variable 1</string> <string name="stringvar2">This is String Variable 2</string> <string name="stringvar3">This is String Variable 3</string> <string name="stringvar4">This is String Variable 4</string> <string name="stringvar5">This is String Variable 5</string> <string name="stringvar6">This is String Variable 6</string> </resources> |
|---|
|
Script
|
echo '<?xml version="1.0" encoding="utf-8"?> <resources>' while read a b do echo ' <string name="'$a'">'$b'</string>' done < $1 echo '</resources>' |
|---|
| FAQ |
|---|
|
Delete files with odd names
|
|
Problem
|
|
我做網站上傳檔案'後來改名稱'結果檔名變成前一個為空白就是
_INDEX.HTM-前面那條線是空白'無法刪除'
|
|
Solution
|
|
先移到跟那個檔案同一個目錄下
然後試試rm ./檔名吧
如果不可以的話....才試試rm -ir .(這樣比較危險一點)
rm -r .的意思是砍掉目前目錄以及其下的子目錄及檔案
加上i的話,系統會在砍掉目錄或檔案前先詢問y or n
回答y才會砍,回答n就不砍,你看到要砍的那個檔案再按y
其他都按n(小心不要按錯了,砍了救不回來的)
|
|
ftp 抓子目錄..
|
|
unix 有沒有甚麼ftp軟體 可以抓子目錄阿... |
|
ncftp:
|
|
ncftp> get -R dir_name
|
|
wget. GNU software.
|
|
An AWK problem
|
|
I am looking through a bunch of files in a directory. The
files I am trying to isolate contain the "046*" in the 3rd record and
the string "TOWER GROUP" in the 6th record. There are many files to go
through and I have tried working with 'grep -l' but that only works in
an ideal situation. The command 'awk' is useful but how do I display
the contents of the entire file if the conditions are met.
|
BEGIN { FS = "," }
$3 ~ /046\*/ && $6 == "TOWER GROUP" {
while( (getline < FILENAME) > 0)
print
close(FILENAME)
}
|
|---|
|
Question : Comparing Number
|
|
I'm trying to compare two numbers.
If the day of the month is less than 10 then echo "larger".
Otherwise, echo "smaller".
|
#!/bin/sh num=date" +%d" echo "\n $num" if expr "$num" \> 10 then echo "larger" else echo "smaller" fi |
|---|